Explore the hospital effect on thrombolysis use, using SHAP values from a single XGBoost model#
Research question: What’s the difference between the SHAP value for patients that attend a hospital, with the SHAP value for patients that do not attend a hospital
Plain English summary#
When fitting a machine learning model to data to make a prediction, it is now possible, with the use of the SHAP library, to allocate contributions of the prediction onto the feature values. This means that we can now turn these black box methods into transparent models and describe what the model used to obtain it’s prediction.
SHAP values are calculated for each feature of each instance for a fitted model. In addition there is the SHAP base value which is the same value for all of the instances. The base value represents the models best guess for any instance without any extra knowledge about the instance (this can also be thought of as the “expected value”). It is possible to obtain the models prediction of an instance by taking the sum of the SHAP base value and each of the SHAP values for the features. This allows the prediction from a model to be transparant, and we can rank the features by their importance in determining the prediction for each instance.
Here we will use the single XGBoost model trained on all of the data, no test set, and read in the SHAP values for this model (from notebook 03a) and focus on understanding the SHAP values for each of the one-hot encoded hosptial features that make up the Stroke team categorical feature.
For example, what is the range of SHAP values for patients that attend the hospital, and for those that do not (as we are representing the hospital feature as a one-hot encoded feature we have a feature for each hospital, so each hospital has a SHAP value when a patient attend another one, so there is a contribution to the prediction based on not attending a hospital).
SHAP values are in the same units as the model output (for XGBoost these are in log odds).
Model and data#
Using the XGBoost model trained on all of the data (no test set used) from notebook 03a_xgb_combined_shap_key_features.ipynb. The 10 features in the model are:
Arrival-to-scan time: Time from arrival at hospital to scan (mins)
Infarction: Stroke type (1 = infarction, 0 = haemorrhage)
Stroke severity: Stroke severity (NIHSS) on arrival
Precise onset time: Onset time type (1 = precise, 0 = best estimate)
Prior disability level: Disability level (modified Rankin Scale) before stroke
Stroke team: Stroke team attended
Use of AF anticoagulents: Use of atrial fibrillation anticoagulant (1 = Yes, 0 = No)
Onset-to-arrival time: Time from onset of stroke to arrival at hospital (mins)
Onset during sleep: Did stroke occur in sleep?
Age: Age (as middle of 5 year age bands)
And one target feature:
Thrombolysis: Did the patient receive thrombolysis (0 = No, 1 = Yes)
Aims#
Using XGBoost model fitted on all the data (no test set) using 10 features
Using SHAP values previously calculated
Understand the SHAP values for each of the hospital one-hot encoded features
Observations#
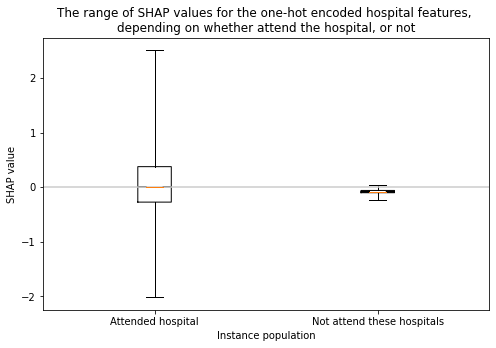
SHAP values for the one-hot encoded hospital features are very dependent on whether the instance attended the hospital or not
SHAP values for the attended one-hot encoded hospital feature are largely one side of zero or the other. There are fewer instances in this population, but the range of SHAP values is wider.
SHAP values for the not attended one-hot encoded hospitals are largely centred on zero. There are more instances in this population, but the range of SHAP values is narrower.
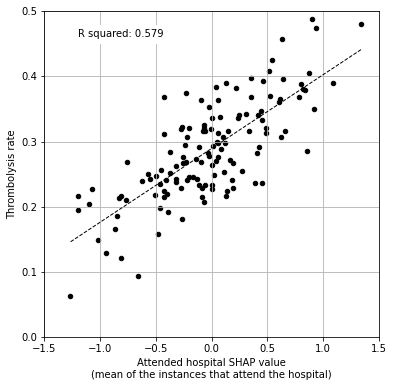
58% of the variability in hospital thrombolysis rate can be explained by the SHAP value for the one-hot encoded hospital feature (the mean of those instances that attend the hospital).
Import libraries#
# Turn warnings off to keep notebook tidy
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Import machine learning methods
from xgboost import XGBClassifier
from os.path import exists
import shap
from scipy import stats
import os
import pickle
import json
# .floor and .ceil
import math
# So can take deep copy
import copy
Set filenames#
# Set up strings (describing the model) to use in filenames
number_of_features_to_use = 10
model_text = f'xgb_{number_of_features_to_use}_features'
notebook = '03b'
Create output folders if needed#
path = './saved_models'
if not os.path.exists(path):
os.makedirs(path)
path = './output'
if not os.path.exists(path):
os.makedirs(path)
path = './predictions'
if not os.path.exists(path):
os.makedirs(path)
Read in JSON file#
Contains a dictionary for plain English feature names for the 8 features selected in the model. Use these as the column titles in the DataFrame.
with open("./output/01_feature_name_dict.json") as json_file:
dict_feature_name = json.load(json_file)
Load data#
Data has previously been split into 5 stratified k-fold splits.
For this exercise, we will fit a model using all of the data (rather than train/test splits used to assess accuracy). We will join up all of the test data (by definition, each instance exists only once across all of the 5 test sets)
data_loc = '../data/kfold_5fold/'
# Initialise empty list
test_data_kfold = []
# Read in the names of the selected features for the model
key_features = pd.read_csv('./output/01_feature_selection.csv')
key_features = list(key_features['feature'])[:number_of_features_to_use]
# And add the target feature name: S2Thrombolysis
key_features.append('S2Thrombolysis')
# For each k-fold split
for i in range(5):
# Read in test set, restrict to chosen features, rename titles, & store
test = pd.read_csv(data_loc + 'test_{0}.csv'.format(i))
test = test[key_features]
test.rename(columns=dict_feature_name, inplace=True)
test_data_kfold.append(test)
# Join all the test sets. Set "ignore_index = True" to reset the index in the
# new dataframe (to run from 0 to n-1), otherwise get duplicate index values
data = pd.concat(test_data_kfold, ignore_index=True)
Get list of feature names#
Before convert stroke team to one-hot encoded features.
feature_names = list(test_data_kfold[0])
Edit data#
Divide into X (features) and y (labels)#
We will separate out our features (the data we use to make a prediction) from our label (what we are trying to predict).
By convention our features are called X (usually upper case to denote multiple features), and the label (thrombolysis or not) y.
X = data.drop('Thrombolysis', axis=1)
y = data['Thrombolysis']
Average thromboylsis (this is the expected outcome of each patient, without knowing anything about the patient)
print (f'Average treatment: {round(y.mean(),2)}')
Average treatment: 0.3
One-hot encode hospital feature#
# Keep copy of original, with 'Stroke team' not one-hot encoded
X_combined = X.copy(deep=True)
# One-hot encode 'Stroke team'
X_hosp = pd.get_dummies(X['Stroke team'], prefix = 'team')
X = pd.concat([X, X_hosp], axis=1)
X.drop('Stroke team', axis=1, inplace=True)
Get model feature names#
With one-hot encoded hospitals
# Get a list of the model feature names
feature_names_ohe = list(X.columns)
XGBoost model#
An XGBoost model was trained on the full dataset (rather than train/test splits used to assess accuracy) in notebook 03a. These models are saved f’./saved_models/03a_{model_text}.p’.
Get SHAP values#
SHAP values give the contribution that each feature has on the models prediction, per instance. A SHAP value is returned for each feature, for each instance.
‘Raw’ SHAP values from XGBoost model are log odds ratios.
In notebook 03a we used the TreeExplainer from the shap library (https://shap.readthedocs.io/en/latest/index.html) to calculate the SHAP values. This is a fast and exact method to estimate SHAP values for tree models and ensembles of tree.
Load SHAP values from pickle (calculated in notebook 03a).
%%time
# Load SHAP values extended (using the explainer model)
filename = f'./output/03a_{model_text}_shap_values_extended.p'
with open(filename, 'rb') as filehandler:
shap_values_extended = pickle.load(filehandler)
CPU times: user 1.59 ms, sys: 60.6 ms, total: 62.2 ms
Wall time: 61.8 ms
The explainer returns the base value which is the same value for all instances [shap_value.base_values], the shap values per feature [shap_value.values]. It also returns the feature dataset values [shap_values.data]. You can (sometimes!) access the feature names from the explainer [explainer.data_feature_names].
Let’s take a look at the data held for the first instance:
.values has the SHAP value for each of the four features.
.base_values has the best guess value without knowing anything about the instance.
.data has each of the feature values
shap_values_extended[0]
.values =
array([ 7.56502628e-01, 4.88319576e-01, 1.10273695e+00, 4.40223962e-01,
4.98975307e-01, 2.02812225e-01, -2.62601525e-01, 3.69181409e-02,
2.30234995e-01, 3.20923195e-04, -6.03703642e-03, -7.17267860e-04,
0.00000000e+00, -4.91688668e-04, 1.20360847e-03, 1.77788886e-03,
-4.34198463e-03, -2.76021136e-04, -2.79896380e-03, 3.52182891e-03,
-2.73969141e-04, 8.53505917e-03, -5.28220041e-03, -8.25227005e-04,
6.20208494e-03, 6.92215608e-03, -6.32244349e-03, -3.35367222e-04,
7.81939551e-03, -4.71850217e-06, -4.25534381e-05, 6.48253039e-03,
8.43156071e-04, -6.28353562e-04, -1.25156669e-02, -7.92063680e-03,
-1.99409085e-03, -5.05548809e-03, -3.90118686e-03, 1.30317558e-03,
0.00000000e+00, -6.48246554e-04, 1.19629130e-03, 8.26304778e-04,
1.28053436e-02, 2.55714403e-03, -3.20375757e-03, 4.23251512e-03,
-7.19791185e-03, 4.02670400e-03, 3.75146419e-03, 8.31848301e-04,
3.45067866e-03, 3.92199913e-03, 1.05317042e-04, 9.53648426e-03,
2.34490633e-03, -1.05699897e-03, -7.75758363e-03, 1.09220366e-03,
0.00000000e+00, 5.15310653e-03, -1.28013985e-02, 7.28079583e-03,
1.98326469e-03, 2.40865033e-04, 6.70310017e-03, 1.18395500e-03,
8.82393331e-04, 2.83133984e-03, 2.06021918e-03, -8.22589453e-03,
5.11038816e-03, -3.25066457e-03, -1.15480982e-02, 9.36000666e-04,
2.03671609e-03, -2.02708528e-03, -5.31264208e-03, 2.42300611e-03,
3.16989725e-04, 3.67143471e-03, -5.07418578e-03, -2.68517504e-03,
3.30522249e-04, -6.63852552e-03, -1.63316587e-03, 1.75383547e-03,
-4.12231544e-03, 1.20234396e-03, -6.25999365e-03, 0.00000000e+00,
-1.00428164e-02, -1.76329317e-03, 3.12283775e-03, 4.69124934e-04,
-1.22163491e-03, 2.30912305e-03, 9.43152234e-04, 1.22348359e-03,
5.29656609e-05, -9.66969132e-03, 3.44762520e-06, -5.46710449e-04,
4.26546484e-03, 4.65912558e-03, 1.30611981e-04, -2.89813057e-03,
-2.98934802e-03, -1.47398096e-03, -2.31104009e-02, -3.47609469e-03,
-5.73671749e-03, 3.97895870e-04, 9.02379164e-04, -5.86819311e-04,
-1.79305486e-03, -5.28960605e-04, -2.10736915e-02, 3.50499223e-03,
-2.04754542e-04, -2.86527374e-03, 1.52953295e-03, -3.72403156e-06,
1.42271689e-03, -2.97368824e-04, 5.06201060e-04, 5.77868486e-04,
-1.44459037e-02, 3.30785802e-03, -2.37809308e-03, -7.35214865e-03,
3.36531224e-03, 1.49519066e-03, -2.46208580e-03, 7.20066251e-04,
6.83251710e-04, -1.92034326e-03, 2.39002449e-03, -8.96935933e-04,
4.85493708e-03], dtype=float32)
.base_values =
-1.1629876
.data =
array([ 17. , 1. , 14. , 1. , 0. , 0. , 186. , 0. , 47.5,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 0. ])
There is one of these for each instance.
shap_values_extended.shape
(88792, 141)
Understand SHAP values for the one-hot encoded hospital features#
We’ve seen above that the categorical feature represented as a one-hot encoded feature have a SHAP value for each of the one-hot encoded features.
For the hospital that the instance attends, the SHAP value for that hosptial represents “the contribution to the prediction due to attending this hospital”. For all of the other hosptials for this instance, the SHAP value for those hospitals represents “the contribution to the prediction from not attending this hospital”.
Here we will focus on understanding the SHAP values for each hospital, their contribution when a patient attends the hospital, and the contribution when the patient does not attend the hospital.
Format the data#
Features are in the same order in shap_values as they are in the original dataset.
Use this to extract the SHAP values for the one-hot encoded hospital features. Create a dataframe containing the SHAP values: an instance per row, and a one-hot encoded hospital feature per column.
# Get list of one-hot encoded hospital column titles
hospital_names_ohe = X.filter(regex='^team',axis=1).columns
n_hospitals = len(hospital_names_ohe)
# Get list of hospital names without the prefix "team_"
hospital_names = [h[5:] for h in hospital_names_ohe]
# Create list of column indices for these hospital column titles (where do the
# hospital features exist in the datasets?)
hospital_columns_index = [X.columns.get_loc(col) for col in hospital_names_ohe]
# Use this index list to access the hosptial shap values (as array)
hosp_shap_values = shap_values_extended.values[:,hospital_columns_index]
# Put in dataframe with hospital as column title
df_hosp_shap_values = pd.DataFrame(hosp_shap_values, columns = hospital_names)
Also include four further columns:
the hospital that the instance attended
contribution from all of the one-hot encoded hospital features
contribution from just the hospital attended
contribution from not attending the rest
# Include Stroke team that each instance attended
df_hosp_shap_values["Stroke team"] = X_combined["Stroke team"].values
# Store the sum of the SHAP values (for all of the hospital features)
df_hosp_shap_values["all_stroke_teams"] = df_hosp_shap_values.sum(axis=1)
# Initialise list for 1) SHAP value for attended hospital 2) SHAP value for
# the sum of the rest of the hospitals
shap_attended_hospital = []
shap_not_attend_these_hospitals = []
# For each patient
for index, row in df_hosp_shap_values.iterrows():
# Get stroke team attended
stroke_team = row["Stroke team"]
# Get SHAP value for the stroke team attended
shap_attended_hospital.append(row[stroke_team])
# Calculate sum of SHAP values for the stroke teams not attend
sum_rest = row["all_stroke_teams"] - row[stroke_team]
shap_not_attend_these_hospitals.append(sum_rest)
# Store two new columns in dataframe
df_hosp_shap_values["attended_stroke_team"] = shap_attended_hospital
df_hosp_shap_values["not_attended_stroke_teams"] = (
shap_not_attend_these_hospitals)
# View preview
df_hosp_shap_values.head()
| AGNOF1041H | AKCGO9726K | AOBTM3098N | APXEE8191H | ATDID5461S | BBXPQ0212O | BICAW1125K | BQZGT7491V | BXXZS5063A | CNBGF2713O | ... | YEXCH8391J | YPKYH1768F | YQMZV4284N | ZBVSO0975W | ZHCLE1578P | ZRRCV7012C | Stroke team | all_stroke_teams | attended_stroke_team | not_attended_stroke_teams | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000321 | -0.006037 | -0.000717 | 0.0 | -0.000492 | 0.001204 | 0.001778 | -0.004342 | -0.000276 | -0.002799 | ... | 0.000720 | 0.000683 | -0.001920 | 0.002390 | -0.000897 | 0.004855 | TXHRP7672C | -0.084398 | -0.023110 | -0.061287 |
| 1 | 0.001207 | -0.002507 | 0.000081 | 0.0 | -0.001356 | 0.001547 | 0.003449 | -0.006348 | -0.000127 | -0.002576 | ... | 0.000148 | 0.000683 | -0.001825 | 0.000454 | -0.001445 | 0.003970 | SQGXB9559U | -0.760522 | -0.671515 | -0.089007 |
| 2 | 0.001492 | -0.015246 | 0.002635 | 0.0 | -0.000272 | 0.001399 | 0.002737 | -0.007848 | -0.000605 | -0.002614 | ... | 0.000135 | 0.000262 | -0.000928 | 0.001229 | -0.001506 | 0.003792 | LFPMM4706C | -1.204099 | -1.084834 | -0.119265 |
| 3 | 0.001255 | 0.002451 | 0.002644 | 0.0 | -0.001359 | 0.000008 | 0.003055 | -0.003141 | -0.000131 | -0.002352 | ... | 0.000705 | 0.000683 | -0.003016 | 0.003507 | -0.000939 | 0.002133 | MHMYL4920B | 0.684426 | 0.737010 | -0.052583 |
| 4 | 0.006129 | -0.004731 | 0.002644 | 0.0 | -0.001359 | 0.000302 | 0.002677 | -0.004384 | 0.000272 | -0.002281 | ... | 0.000892 | 0.000010 | -0.001976 | 0.001467 | -0.000799 | 0.002244 | EQZZZ5658G | -0.088429 | 0.028813 | -0.117242 |
5 rows × 136 columns
Boxplot (all hospitals together)#
Analyse the range of SHAP values for the one-hot encoded hospital features. Show as two populations: 1) the attended hospital, 2) the sum of the hospitals not attended
fig = plt.figure(figsize=(8,5))
ax = fig.add_subplot(1,1,1)
ax.boxplot([shap_attended_hospital, shap_not_attend_these_hospitals],
labels=["Attended hospital", "Not attend these hospitals"],
whis=99999, notch=True);
title = ("The range of SHAP values for the one-hot encoded hospital features, "
"\ndepending on whether attend the hospital, or not")
# Add line at Shap = 0
ax.plot([plt.xlim()[0], plt.xlim()[1]], [0,0], c='0.8')
ax.set_title(title)
ax.set_xlabel("Instance population")
ax.set_ylabel("SHAP value");
plt.savefig(f'./output/{notebook}_{model_text}'
f'_hosp_shap_attend_vs_notattend_boxplot.jpg', dpi=300,
bbox_inches='tight', pad_inches=0.2)
plt.show()
Boxplot (individual hospitals)#
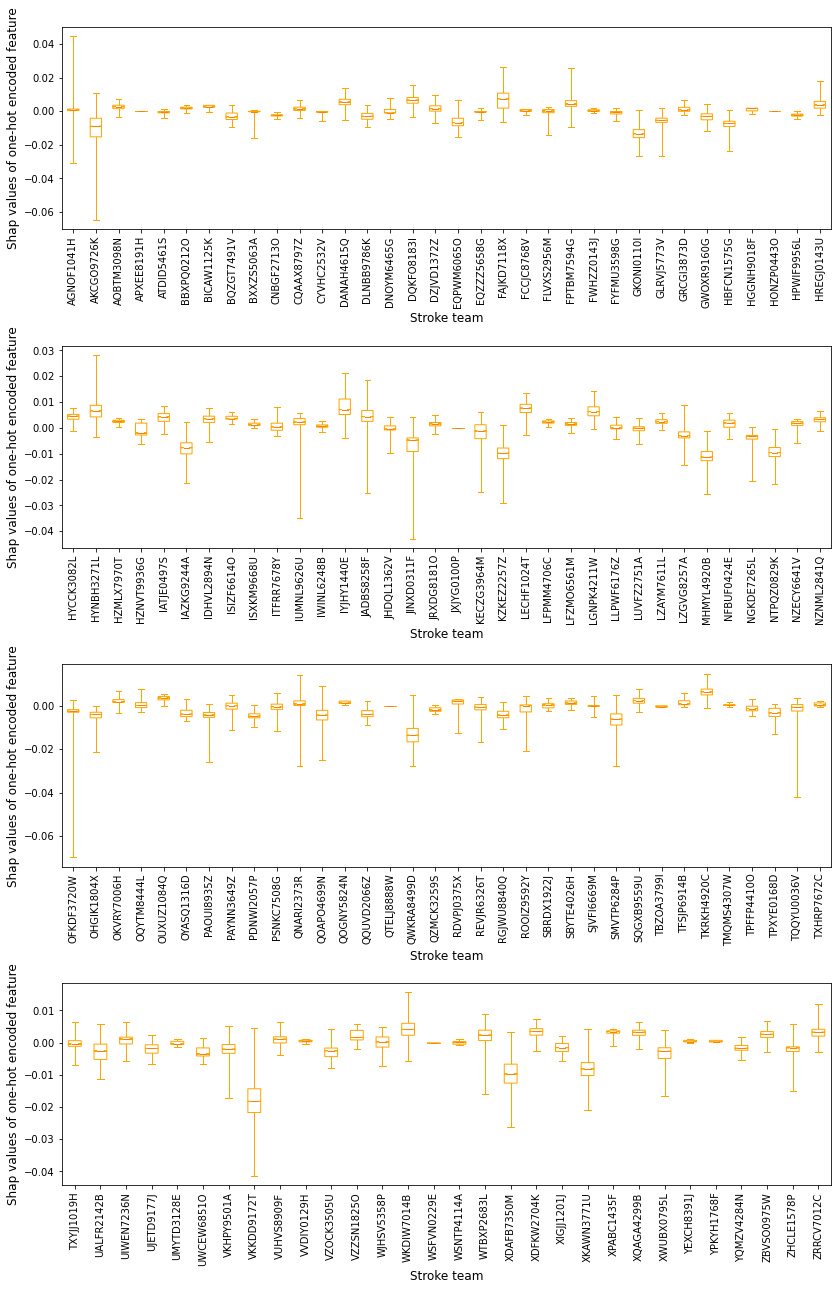
Create a boxplot to show the range of SHAP values for each individual one-hot encoded hospital feature.
Show the SHAP value as two populations: 1) the group of instances that attend the hospital [black], and 2) the group of instances that do not attend the hosptial [orange].
Order the hospitals in descending order of mean SHAP value for the hospital the instance attended (so those that more often contribute to a yes-thrombolysis decision, through to those that most often contribute to a no-thrombolysis decision).
Firstly, to order the hospitals, create a dataframe containing the mean SHAP value for each hosptial (for those instances that attended the hospital)
# Initialise lists
attend_stroketeam_min = []
attend_stroketeam_q1 = []
attend_stroketeam_mean = []
attend_stroketeam_q3 = []
attend_stroketeam_max = []
# For each hospital, store descriptive statistics of SHAP values for those
# instances that attend the hospital
for h in hospital_names:
mask = df_hosp_shap_values['Stroke team'] == h
data_stroke_team = df_hosp_shap_values[h][mask]
q1, q3 = np.percentile(data_stroke_team, [25,75])
attend_stroketeam_min.append(data_stroke_team.min())
attend_stroketeam_q1.append(q1)
attend_stroketeam_mean.append(data_stroke_team.mean())
attend_stroketeam_q3.append(q3)
attend_stroketeam_max.append(data_stroke_team.max())
# Create dataframe with 6 columns
df_hosp_shap_value_stats = pd.DataFrame(hospital_names, columns=["hospital"])
df_hosp_shap_value_stats["shap_min"] = attend_stroketeam_min
df_hosp_shap_value_stats["shap_q1"] = attend_stroketeam_q1
df_hosp_shap_value_stats["shap_mean"] = attend_stroketeam_mean
df_hosp_shap_value_stats["shap_q3"] = attend_stroketeam_q3
df_hosp_shap_value_stats["shap_max"] = attend_stroketeam_max
# sort in descending mean SHAP value order
df_hosp_shap_value_stats.sort_values("shap_mean", ascending=False, inplace=True)
df_hosp_shap_value_stats.head(5)
| hospital | shap_min | shap_q1 | shap_mean | shap_q3 | shap_max | |
|---|---|---|---|---|---|---|
| 9 | CNBGF2713O | 0.648626 | 1.160532 | 1.338743 | 1.513107 | 1.989456 |
| 25 | GKONI0110I | 0.046286 | 0.888337 | 1.085008 | 1.286739 | 1.779779 |
| 62 | MHMYL4920B | 0.130139 | 0.786147 | 0.933300 | 1.059232 | 1.476519 |
| 65 | NTPQZ0829K | 0.209000 | 0.763998 | 0.917956 | 1.126985 | 1.599991 |
| 32 | HPWIF9956L | 0.206888 | 0.652731 | 0.901027 | 1.152177 | 1.624375 |
Add admission figures to xlabel in boxplot
Create dataframe with admissions and thrombolysis rate per stroke team (index)
# Get Stroke team name, the stroke team admission numbers, and list of SHAP
# values for each instance that attended teh stroke team
unique_stroketeams_list = list(set(X_combined["Stroke team"]))
admissions = [X[f'team_{s}'].sum() for s in unique_stroketeams_list]
df_stroketeam_ivt_adms = pd.DataFrame(unique_stroketeams_list,
columns=["Stroke team"])
df_stroketeam_ivt_adms["Admissions"] = admissions
df_stroketeam_ivt_adms.set_index("Stroke team", inplace=True)
df_stroketeam_ivt_adms.sort_values("Admissions", ascending=True, inplace=True)
# Calculate IVT rate per hosptial
hosp_ivt_rate = data.groupby(by=["Stroke team"]).mean()["Thrombolysis"]
# Join IVT rate with admissions per hosptial
df_stroketeam_ivt_adms = df_stroketeam_ivt_adms.join(hosp_ivt_rate)
df_stroketeam_ivt_adms
| Admissions | Thrombolysis | |
|---|---|---|
| Stroke team | ||
| JXJYG0100P | 120 | 0.233333 |
| VVDIY0129H | 130 | 0.192308 |
| YEXCH8391J | 149 | 0.228188 |
| CNBGF2713O | 152 | 0.480263 |
| XPABC1435F | 166 | 0.216867 |
| ... | ... | ... |
| JINXD0311F | 1377 | 0.368192 |
| AKCGO9726K | 1428 | 0.369748 |
| OFKDF3720W | 1488 | 0.228495 |
| FPTBM7594G | 1645 | 0.321581 |
| FAJKD7118X | 1980 | 0.275758 |
132 rows × 2 columns
Create data for boxplot. Using order of hospitals from the hosp_shap_stats_df dataframe.
# Go through this order of hospitals
hospital_order = df_hosp_shap_value_stats["hospital"]
# Create list of SHAP main effect values (one per hospital) for instances that
# attend stroke team
attend_stroketeam_groups_ordered = []
not_attend_stroketeam_groups_ordered = []
# Create list of labels for boxplot "stroke team name (admissions)"
xlabel = []
# Through hospital in defined order (as determined above)
for h in hospital_order:
# Attend
mask = df_hosp_shap_values['Stroke team'] == h
attend_stroketeam_groups_ordered.append(df_hosp_shap_values[h][mask])
# Not attend
mask = df_hosp_shap_values['Stroke team'] != h
not_attend_stroketeam_groups_ordered.append(df_hosp_shap_values[h][mask])
# Label
ivt_rate = int(df_stroketeam_ivt_adms['Thrombolysis'].loc[h] * 100)
xlabel.append(f"{h} ({df_stroketeam_ivt_adms['Admissions'].loc[h]}, "
f"{ivt_rate}%)")
Plot the boxplot
Resource for using overall y min and max of both datasets on the 4 plots so have the same range: https://blog.finxter.com/how-to-find-the-minimum-of-a-list-of-lists-in-python/#:~:text=With%20the%20key%20argument%20of,of%20the%20list%20of%20lists
# Plot 34 hospitals on each figure to aid readability
print("Shows the range of contributions to the prediction from this hospital "
"when patients 1) do [black], and 2) do not [orange] attend this "
"hospital")
# Group the hospitals into 34
st = 0
ed = 34
inc = ed
max_size = n_hospitals
# Use overall y min & max of both datasets on the 4 plots so have same range
ymin1 = min(min(attend_stroketeam_groups_ordered, key=min))
ymin2 = min(min(not_attend_stroketeam_groups_ordered, key=min))
ymax1 = max(max(attend_stroketeam_groups_ordered, key=max))
ymax2 = max(max(not_attend_stroketeam_groups_ordered, key=max))
ymin = min(ymin1, ymin2)
ymax = max(ymax1, ymax2)
# Adjust min and max to accommodate some wriggle room
yrange = ymax - ymin1
ymin = ymin - yrange/50
ymax = ymax + yrange/50
# Create figure with 4 subplots
fig = plt.figure(figsize=(12,25))
# Create four subplots
for subplot in range(4):
ax = fig.add_subplot(4,1,subplot+1)
# The contribution from this hospital when patients don't attend this
# hospital
c1 = "orange"
c2 = "orange"
c3 = "white"
ax.boxplot(not_attend_stroketeam_groups_ordered[st:ed],
labels=xlabel[st:ed],
whis=99999, patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
# The contribution from this hospital when patients do attend this hosptial
c1 = "black"
c2 = "black"
c3 = "white"
ax.boxplot(attend_stroketeam_groups_ordered[st:ed],
labels=xlabel[st:ed],
whis=99999, patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
plt.ylabel('SHAP values (one-hot encoded hospital feature)',size=12)
plt.xlabel('Stroke team (admissions, IVT rate)',size=12)
plt.ylim(ymin, ymax)
plt.xticks(rotation=90)
# Add line at Shap = 0
plt.plot([plt.xlim()[0], plt.xlim()[1]], [0,0], c='0.8')
st = min(st+inc,max_size)
ed = min(ed+inc,max_size)
plt.subplots_adjust(bottom=0.25, wspace=0.05)
plt.tight_layout(pad=2)
plt.savefig(f'./output/{notebook}_{model_text}'
f'_individual_hosp_shap_attend_vs_notattend_boxplot.jpg', dpi=300,
bbox_inches='tight', pad_inches=0.2)
plt.show()
Shows the range of contributions to the prediction from this hospital when patients 1) do [black], and 2) do not [orange] attend this hospital
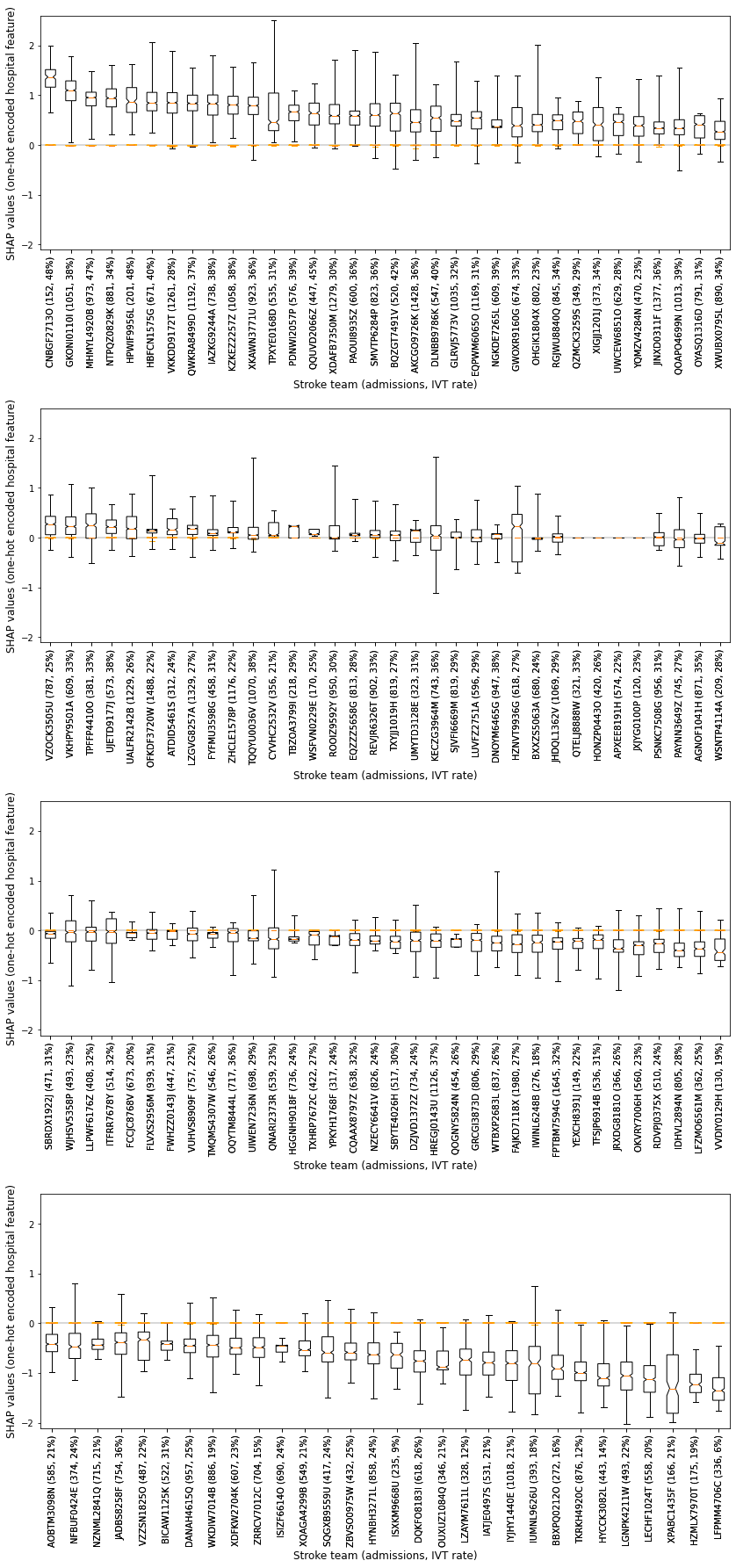
Notice that when patients do not attend the hospital, the range of the SHAP values are largely centred on zero. When patients do attend hosptial, the range of SHAP values are largely on one side of zero, or the other.
iqr_below_zero = df_hosp_shap_value_stats["shap_q3"] < 0
iqr_spans_zero = (df_hosp_shap_value_stats["shap_q1"] *
df_hosp_shap_value_stats["shap_q3"])
iqr_above_zero = df_hosp_shap_value_stats["shap_q1"] > 0
iqr_is_zero1 = df_hosp_shap_value_stats["shap_q1"] == 0
iqr_is_zero2 = df_hosp_shap_value_stats["shap_q3"] == 0
iqr_is_zero = iqr_is_zero1 * iqr_is_zero2
print (f"There are {iqr_below_zero.sum()} hospitals whose interquartile range "
f"is below zero")
print (f"There are {iqr_spans_zero.lt(0).sum()} hospitals whose interquartile "
f"range spans zero")
print (f"There are {iqr_above_zero.sum()} hospitals whose interquartile range "
f"is above zero")
print (f"There are {iqr_is_zero.sum()} hospitals whose interquartile range is "
f"zero")
There are 58 hospitals whose interquartile range is below zero
There are 24 hospitals whose interquartile range spans zero
There are 46 hospitals whose interquartile range is above zero
There are 4 hospitals whose interquartile range is zero
How does the SHAP value for the attended one-hot encoded hospital feature compare to the thrombolysis rate of the hospital?
Create dataframe containing the hospital’s IVT rate and SHAP value (for those patients that attend the hospital).
hosp_ivt_rate = data.groupby(by=["Stroke team"]).mean()["Thrombolysis"]
df_hosp_plot = (
df_hosp_shap_value_stats[["shap_mean","hospital"]].copy(deep=True))
df_hosp_plot.set_index("hospital", inplace=True)
df_hosp_plot = df_hosp_plot.join(hosp_ivt_rate)
df_hosp_plot
| shap_mean | Thrombolysis | |
|---|---|---|
| hospital | ||
| CNBGF2713O | 1.338743 | 0.480263 |
| GKONI0110I | 1.085008 | 0.389153 |
| MHMYL4920B | 0.933300 | 0.473792 |
| NTPQZ0829K | 0.917956 | 0.349603 |
| HPWIF9956L | 0.901027 | 0.487562 |
| ... | ... | ... |
| LGNPK4211W | -1.069179 | 0.227181 |
| LECHF1024T | -1.097267 | 0.204301 |
| XPABC1435F | -1.196877 | 0.216867 |
| HZMLX7970T | -1.198507 | 0.194286 |
| LFPMM4706C | -1.271484 | 0.062500 |
132 rows × 2 columns
Plot SHAP value for one-hot encoded hospital feature (mean for those instances that attend the hospital) vs hospital IVT rate
# Setup data for chart
x = df_hosp_plot['shap_mean']
y = df_hosp_plot['Thrombolysis']
# Fit a regression line to the points
slope, intercept, r_value, p_value, std_err = \
stats.linregress(x, y)
r_square = r_value ** 2
y_pred = intercept + (x * slope)
# Create scatter plot with regression line
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
ax.scatter(x, y, color='black', marker='o', s=20)
ax.plot (x, y_pred, color = 'k', linestyle='--', linewidth=1)
# Set chart limits
ax.set_ylim(0, 0.5)
ax.set_xlim(-1.5, 1.5)
# Add textbox
text = f'R squared: {r_square:.3f}'
ax.text(-1.2, 0.46, text,
bbox=dict(facecolor='white', edgecolor='white'))
# Chart titles
ax.set_xlabel("Attended hospital SHAP value"
"\n(mean of the instances that attend the hospital)")
ax.set_ylabel('Thrombolysis rate')
plt.grid()
plt.savefig(f'./output/{notebook}_{model_text}'
f'_attended_hosp_shap_vs_ivt_rate.jpg', dpi=300,
bbox_inches='tight', pad_inches=0.2)
plt.show()
f = ('formula: ' + str("{:.2f}".format(slope)) + 'x + ' +
str("{:.2f}".format(intercept)))
print (f'R squared: {r_square:.3f}\np: {p_value:0.4f}\nformula: {f}')
R squared: 0.579
p: 0.0000
formula: formula: 0.11x + 0.29
Extra code#
There was a journey to analyse the data and arrive at the boxplot (that we found to be the best visualisation yet to summarise this data).
Below are the other ways that we looked at the data, that led us to use the boxplot.
View descriptive stats
df_hosp_shap_values.describe()
| AGNOF1041H | AKCGO9726K | AOBTM3098N | APXEE8191H | ATDID5461S | BBXPQ0212O | BICAW1125K | BQZGT7491V | BXXZS5063A | CNBGF2713O | ... | XWUBX0795L | YEXCH8391J | YPKYH1768F | YQMZV4284N | ZBVSO0975W | ZHCLE1578P | ZRRCV7012C | all_stroke_teams | attended_stroke_team | not_attended_stroke_teams | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 88792.000000 | 88792.000000 | 88792.000000 | 88792.0 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | ... | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 | 88792.000000 |
| mean | 0.001127 | -0.002248 | -0.000125 | 0.0 | 0.000002 | -0.000846 | 0.000121 | 0.000189 | -0.000461 | -0.000242 | ... | -0.000391 | -0.000049 | -0.000210 | 0.000426 | -0.000371 | -0.000114 | -0.000647 | -0.037682 | 0.042369 | -0.080051 |
| std | 0.013528 | 0.082680 | 0.039048 | 0.0 | 0.015024 | 0.051438 | 0.034849 | 0.050091 | 0.013646 | 0.056630 | ... | 0.039715 | 0.013549 | 0.011468 | 0.035839 | 0.043886 | 0.020340 | 0.049949 | 0.560754 | 0.549480 | 0.033426 |
| min | -0.389735 | -0.294640 | -0.987508 | 0.0 | -0.221226 | -1.461526 | -0.733899 | -0.482234 | -0.262650 | -0.004530 | ... | -0.328137 | -0.792791 | -0.296149 | -0.328538 | -1.204027 | -0.213830 | -1.240766 | -2.085642 | -2.018145 | -0.233494 |
| 25% | 0.000334 | -0.015132 | 0.001455 | 0.0 | -0.000965 | 0.001333 | 0.002318 | -0.004953 | -0.000319 | -0.002886 | ... | -0.004907 | 0.000204 | 0.000262 | -0.002390 | 0.001578 | -0.002748 | 0.001935 | -0.363692 | -0.271972 | -0.099802 |
| 50% | 0.000775 | -0.008884 | 0.002641 | 0.0 | -0.000498 | 0.001857 | 0.002737 | -0.003369 | -0.000220 | -0.002531 | ... | -0.002697 | 0.000317 | 0.000262 | -0.001799 | 0.002549 | -0.001633 | 0.003190 | -0.064071 | 0.010659 | -0.079233 |
| 75% | 0.001255 | -0.003960 | 0.003523 | 0.0 | -0.000203 | 0.002346 | 0.003449 | -0.001076 | -0.000080 | -0.002174 | ... | -0.001574 | 0.000667 | 0.000683 | -0.000900 | 0.003388 | -0.001342 | 0.004121 | 0.304690 | 0.377607 | -0.058291 |
| max | 0.504174 | 2.055953 | 0.329712 | 0.0 | 0.592340 | 0.262388 | 0.003869 | 1.405697 | 0.881546 | 1.989456 | ... | 0.929842 | 0.049373 | 0.000864 | 1.315028 | 0.283344 | 0.744248 | 0.176605 | 2.409183 | 2.507814 | 0.033592 |
8 rows × 135 columns
Are there any hospitals that only have one value for all instances? This indicates that the feature was not used to divide a node in any of the trees.
print("These hospitals have the same SHAP value for all patients")
for h in hospital_names:
if df_hosp_shap_values[h].nunique() == 1:
print(f"{h} has SHAP value {df_hosp_shap_values[h].unique()[0]} for all"
f" instances")
These hospitals have the same SHAP value for all patients
APXEE8191H has SHAP value 0.0 for all instances
HONZP0443O has SHAP value 0.0 for all instances
JXJYG0100P has SHAP value 0.0 for all instances
QTELJ8888W has SHAP value 0.0 for all instances
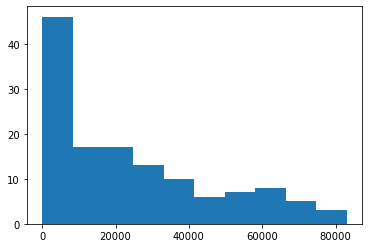
What’s the range of number of unique values for each hospital for all patients?
print ("The count of unique SHAP values for each hospital")
n_unique_per_hosptial = [
df_hosp_shap_values[h].nunique() for h in hospital_names]
fig, axes = plt.subplots(1)
axes.hist(n_unique_per_hosptial);
The count of unique SHAP values for each hospital
Is there a relationship between number of unique SHAP values, and hospital admission numnbers?
# Calculate the number of admissions per hospital
admissions = [X[h].sum() for h in hospital_names_ohe]
# Calculate number of unique SHAP values
n_unique_per_hosptial_all_instances = [
df_hosp_shap_values[h].nunique() for h in hospital_names]
# Calculate number of unique SHAP values for patients that attend
n_unique_per_hosptial_attend = []
n_unique_per_hosptial_not_attend = []
for h in hospital_names:
mask = df_hosp_shap_values["Stroke team"] == h
n_unique_per_hosptial_attend.append(df_hosp_shap_values[h][mask].nunique())
mask = np.logical_not(mask)
n_unique_per_hosptial_not_attend.append(
df_hosp_shap_values[h][mask].nunique())
# Store in dataframe
df_hospital_details = pd.DataFrame(admissions, columns=["admissions"])
df_hospital_details["number_of_unique_shap_values"] = (
n_unique_per_hosptial_all_instances)
df_hospital_details["number_of_unique_shap_values_attend"] = (
n_unique_per_hosptial_attend)
df_hospital_details["number_of_unique_shap_values_not_attend"] = (
n_unique_per_hosptial_not_attend)
df_hospital_details["Stroke team"] = hospital_names
# Plot 1: Admissions vs number of unique SHAP values
# All instances contributing to SHAP value count
df_hospital_details.plot.scatter(x="admissions",
y="number_of_unique_shap_values")
# Plot 2: Admissions vs number of unique SHAP values
# Only instances that attend hosptial contributing to SHAP value count
ax = df_hospital_details.plot.scatter(x="admissions",
y="number_of_unique_shap_values_attend")
# Include x = y line (shows the max number of of unique values)
max_axis_value = max(ax.get_xlim()[1], ax.get_ylim()[1])
ax.plot([0, max_axis_value], [0, max_axis_value], c='0.5')
# Plot 3: Admissions vs number of unique SHAP values
# Only instances that do not attend hosptial contributing to SHAP value count
df_hospital_details.plot.scatter(x="admissions",
y="number_of_unique_shap_values_not_attend")
<AxesSubplot:xlabel='admissions', ylabel='number_of_unique_shap_values_not_attend'>
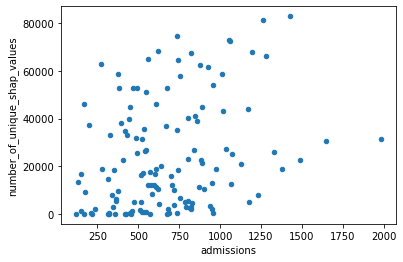
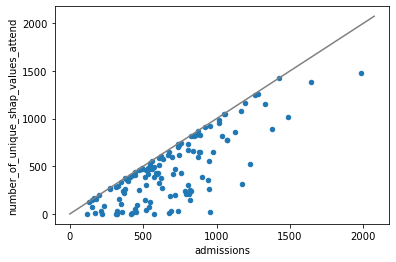
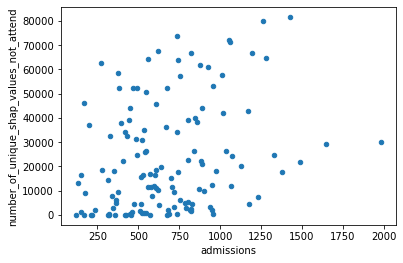
Let’s look at a hospital with the most unique values
row_index = df_hospital_details["number_of_unique_shap_values"].idxmax()
stroke_team_max_n_unique = df_hospital_details["Stroke team"].iloc[row_index]
print(f"Hospital {stroke_team_max_n_unique} has "
f"{df_hospital_details['number_of_unique_shap_values'].max()} "
f"unique values")
Hospital AKCGO9726K has 82921 unique values
Look at descriptive stats for this hospital
df_hosp_shap_values[stroke_team_max_n_unique].describe()
count 88792.000000
mean -0.002248
std 0.082680
min -0.294640
25% -0.015132
50% -0.008884
75% -0.003960
max 2.055953
Name: AKCGO9726K, dtype: float64
What’s the difference between the SHAP value for this hospital for the instances that attended it, compared to those instances that didn’t?
Colour histogram bars to represent: Green for positive SHAP value, Grey for 0, and Red for negative SHAP value.
def create_histogram_with_colours(data, bins, ax):
"""
data [DataFrame]: Single column of data containing values in the histogram
bins [int]: Width of each histogram bar
ax [object]: Matplotlib axes object
Histogram bars are:
green if positive value
black if spans zero
red if negative value
Function return matplotlib axes object
"""
N, bins, patches = ax.hist(data, edgecolor='white', linewidth=0.2,
bins=bins);
for i in range(N.shape[0]):
if bins[i] < 0 and bins[i+1] < 0:
patches[i].set_facecolor('red')
elif bins[i] > 0 and bins[i+1] > 0:
patches[i].set_facecolor('green')
else:
patches[i].set_facecolor('black')
return(ax)
stroke_team = stroke_team_max_n_unique
mask1 = df_hosp_shap_values["Stroke team"] == stroke_team
shap_values_attend = df_hosp_shap_values[stroke_team][mask1]
mask2 = np.logical_not(mask1)
shap_values_not_attend = df_hosp_shap_values[stroke_team][mask2]
# Plot histogram of SHAP values for all instances
fig, ax = plt.subplots()
create_histogram_with_colours(df_hosp_shap_values[stroke_team], 100, ax)
ax.set_xlabel(f"SHAP")
ax.set_ylabel("Number of instances")
print(f"{stroke_team}. Number of unique values for all patients (attended or "
f"not): {df_hosp_shap_values[stroke_team].nunique()}")
print(f"Number of patients {df_hosp_shap_values[stroke_team].shape[0]}")
plt.show
# Plot histogram of SHAP values for instances attend hospital
mask1 = mask1 * 1
s1 = mask1.sum()
fig, ax = plt.subplots()
ax = create_histogram_with_colours(shap_values_attend, 100, ax)
ax.set_xlabel(f"SHAP")
ax.set_ylabel("Number of instances")
print(f"{stroke_team}. Number of unique values for those patients who "
f"attended: {shap_values_attend.nunique()}")
print(f"Number of patients {s1}")
plt.show
# Plot histogram of SHAP values for instances not attend hospital
mask2 = mask2 * 1
s2 = mask2.sum()
fig, ax = plt.subplots()
ax = create_histogram_with_colours(shap_values_not_attend, 100, ax)
ax.set_xlabel(f"SHAP")
ax.set_ylabel("Number of instances")
print(f"{stroke_team}. Number of unique values for those patients who do not "
f"attended: {shap_values_not_attend.nunique()}")
print(f"Number of patients {s2}")
plt.show
AKCGO9726K. Number of unique values for all patients (attended or not): 82921
Number of patients 88792
AKCGO9726K. Number of unique values for those patients who attended: 1421
Number of patients 1428
AKCGO9726K. Number of unique values for those patients who do not attended: 81500
Number of patients 87364
<function matplotlib.pyplot.show(close=None, block=None)>
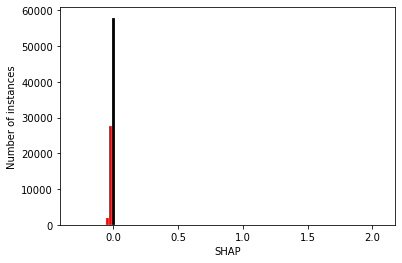
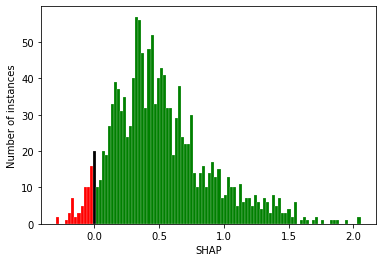
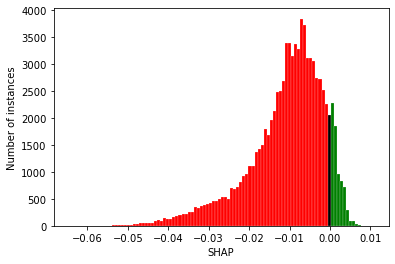
So there’s two populations, but in the top plot you can not see the histogram for the instances that attended the hospital, as their frequency is too few and the plot is dominated by the frequency range for the number of patients who did not attend the hosptial.
Those that attend have a higher SHAP value, but there’s fewer instances so can not see these values. Those that do not attend have a low SHAP value, a smaller range of values, but far more instances, so dominates the y axis, but can not see the spread (as the other population has determines the x axis range).
Better to view as two populations.
Plot a boxplot for the SHAP values of each hospital (for all instances)
# Create list of values for each boxplot (one per hospital)
stroketeam_groups = []
for h in hospital_names:
stroketeam_groups.append(df_hosp_shap_values[h])
# Create a figure with 35 hospitals in each to aid visually
print("Shows the range of contributions to the prediction from this hospital "
"for all the instances")
# To group the hospitals into 34
st = 0
ed = 34
inc = ed
max_size = n_hospitals
# Plot properties
c1 = "navy"
c2 = "navy"
c3 = "white"
# Create figure with 4 subplots
fig = plt.figure(figsize=(12,18))
# Create four subplots
for subplot in range(4):
ax = fig.add_subplot(4,1,subplot+1)
ax.boxplot(stroketeam_groups[st:ed],
labels=df_hosp_shap_values.columns[st:ed],
whis=9999999, patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
plt.ylabel('Shap values of one-hot encoded feature',size=12)
plt.xlabel('Stroke team',size=12)
plt.xticks(rotation=90)
st = min(st+inc,max_size)
ed = min(ed+inc,max_size)
plt.subplots_adjust(bottom=0.25, wspace=0.05)
plt.tight_layout(pad=2)
plt.show()
Shows the range of contributions to the prediction from this hospital for all the instances
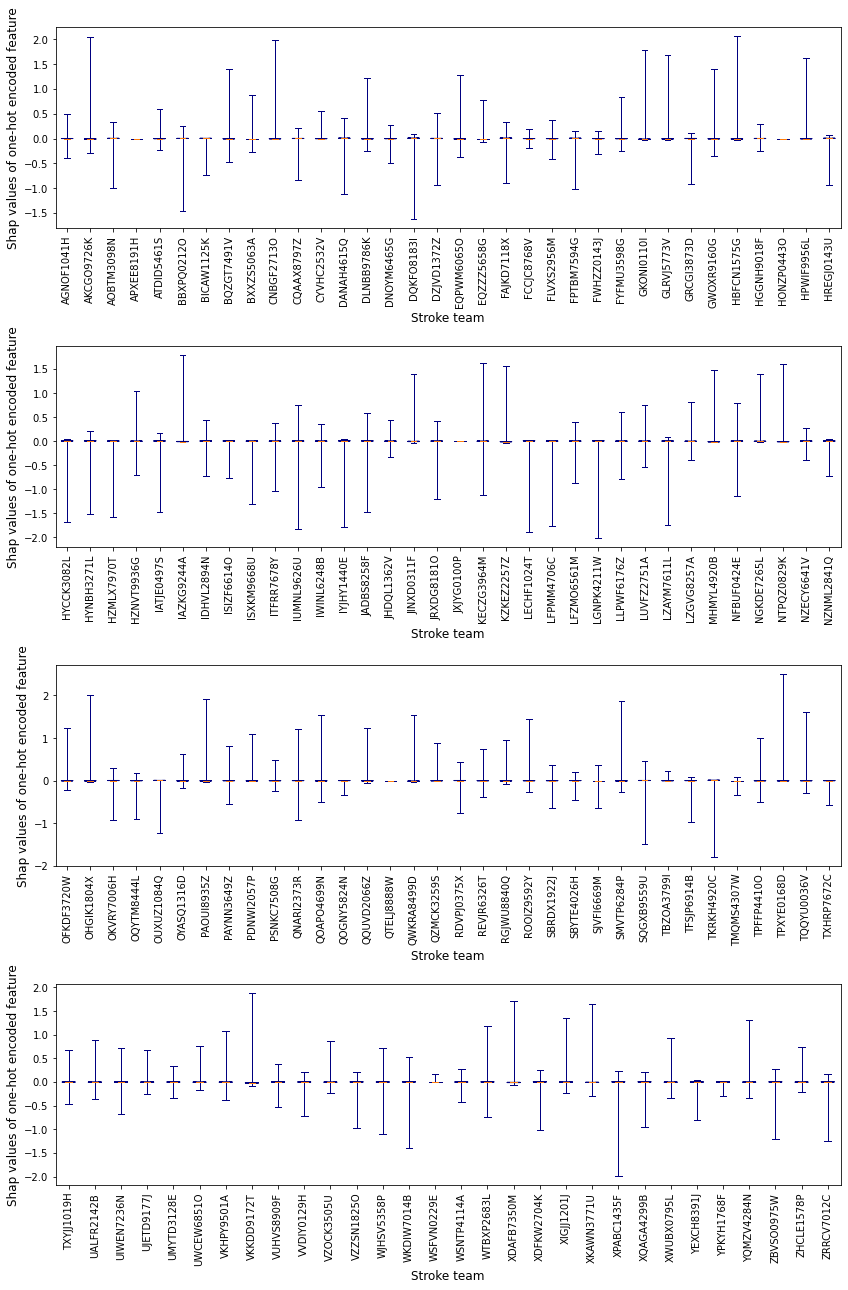
Shows that hospitals have the majority of their cases at value 0, and some have a longer range than others, with most having their range entirely on one side of 0 or the other.
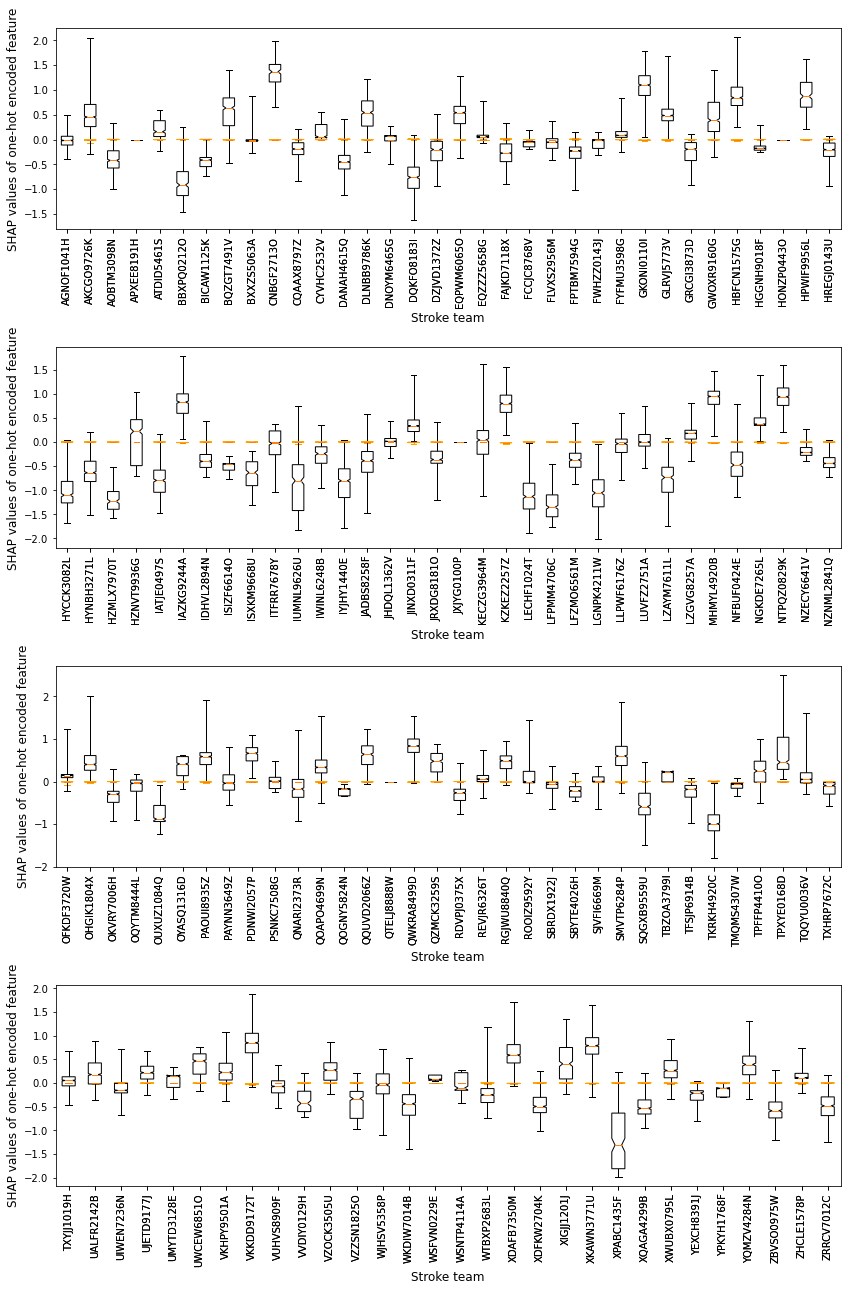
Let’s plot it again, twice, showing only those instances that go to the hospital, and again when they do not.
Include instances that attend the hospital only
# Create list of values for each boxplot (one per hospital), only include SHAP
# value for instances that attend stroke team
attend_stroketeam_groups = []
for h in hospital_names:
mask = df_hosp_shap_values['Stroke team'] == h
attend_stroketeam_groups.append(df_hosp_shap_values[h][mask])
# Create a figure with 35 hospitals in each to aid visually
print("Shows the range of contributions to the prediction from this hospital "
"when patients attend this hosptial")
# To group the hospitals into 34
st = 0
ed = 34
inc = ed
max_size = n_hospitals
# Plot properties
c1 = "black"
c2 = "black"
c3 = "white"
# Create figure with 4 subplots
fig = plt.figure(figsize=(12,18))
# Create four subplots
for subplot in range(4):
ax = fig.add_subplot(4,1,subplot+1)
ax.boxplot(attend_stroketeam_groups[st:ed],
labels=df_hosp_shap_values.columns[st:ed],
whis=999999,patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
plt.ylabel('Shap values of one-hot encoded feature',size=12)
plt.xlabel('Stroke team',size=12)
plt.xticks(rotation=90)
st = min(st+inc,max_size)
ed = min(ed+inc,max_size)
plt.subplots_adjust(bottom=0.25, wspace=0.05)
plt.tight_layout(pad=2)
plt.show()
Shows the range of contributions to the prediction from this hospital when patients attend this hosptial
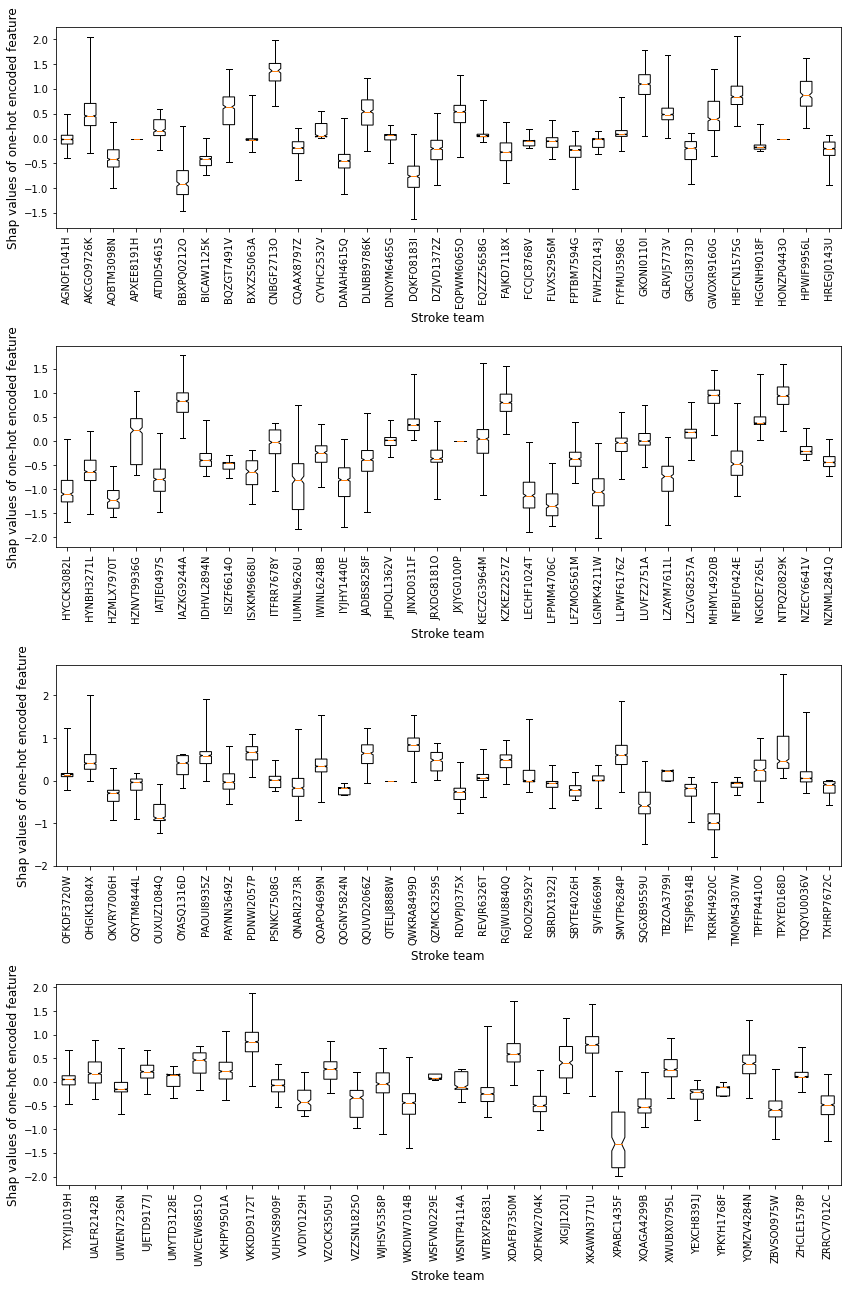
Edit data so only contains instances when not go to hospital
# Only include SHAP value for instances that do not attend stroke team
not_attend_stroketeam_groups = []
for h in hospital_names:
mask = df_hosp_shap_values['Stroke team'] != h
not_attend_stroketeam_groups.append(df_hosp_shap_values[h][mask])
# Create a figure with 35 hospitals in each to aid visually
print("Shows the range of contributions to the prediction from this hospital "
"when patients do not attend this hosptial")
# To group the hospitals into 34
st = 0
ed = 34
inc = ed
max_size = n_hospitals
# Plot properties
c1 = "orange"
c2 = "orange"
c3 = "white"
# Create figure with 4 subplots
fig = plt.figure(figsize=(12,18))
# Create four subplots
for subplot in range(4):
ax = fig.add_subplot(4,1,subplot+1)
ax.boxplot(not_attend_stroketeam_groups[st:ed],
labels=df_hosp_shap_values.columns[st:ed],
whis=999999,patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
plt.ylabel('Shap values of one-hot encoded feature',size=12)
plt.xlabel('Stroke team',size=12)
plt.xticks(rotation=90)
st = min(st+inc,max_size)
ed = min(ed+inc,max_size)
plt.subplots_adjust(bottom=0.25, wspace=0.05)
plt.tight_layout(pad=2)
plt.show()
Shows the range of contributions to the prediction from this hospital when patients do not attend this hosptial
# Two box plots on 1 plot (spread of SHAP when instance attend, and not attend,
# hospital)
# Create a figure with 35 hospitals in each to aid visually
print("Shows the range of contributions to the prediction from this hospital "
"when patients 1) do [black], and 2) do not [orange] attend this "
"hosptial")
# To group the hospitals into 34
st = 0
ed = 34
inc = ed
max_size = n_hospitals
# Create figure with 4 subplots
fig = plt.figure(figsize=(12,18))
# Create four subplots
for subplot in range(4):
ax = fig.add_subplot(4,1,subplot+1)
# The contribution from this hospital when patients do not attend this
# hosptial
c1 = "orange"
c2 = "orange"
c3 = "white"
ax.boxplot(not_attend_stroketeam_groups[st:ed],
labels=df_hosp_shap_values.columns[st:ed],
whis=99999,patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
# The contribution from this hospital when patients do attend this hosptial
c1 = "black"
c2 = "black"
c3 = "white"
ax.boxplot(attend_stroketeam_groups[st:ed],
labels=df_hosp_shap_values.columns[st:ed],
whis=99999,patch_artist=True, notch=True,
boxprops=dict(facecolor=c3, color=c1),
capprops=dict(color=c1),
whiskerprops=dict(color=c1),
flierprops=dict(color=c1, markeredgecolor=c1),
meanprops=dict(color=c2))
plt.ylabel('SHAP values of one-hot encoded feature',size=12)
plt.xlabel('Stroke team',size=12)
plt.xticks(rotation=90)
st = min(st+inc,max_size)
ed = min(ed+inc,max_size)
plt.subplots_adjust(bottom=0.25, wspace=0.05)
plt.tight_layout(pad=2)
plt.show()
Shows the range of contributions to the prediction from this hospital when patients 1) do [black], and 2) do not [orange] attend this hosptial
Does it help understanding to represent this as histograms?
Create three matrix of histograms.
One with all the instances to each hosptial
One with just the instances that attend each hosptial
One with just the instances that don’t attend each hosptial.
One with all the instances to each hosptial (forcing same axis ranges)
# Find the largest value used for the y axis in all of the histograms in the
# subplots (use this to set the max for each subplot)
y_max = -1
x_min = 99
x_max = -99
fig, axes = plt.subplots(1)
for h in hospital_names:
# Plot histogram
axes.hist(df_hosp_shap_values[h])
# Get axis limits
ylims = axes.get_ylim()
# Store if greater than found so far
y_max = max(y_max, ylims[1])
# Get axis limits
xlims = axes.get_xlim()
# Store if greater than found so far
x_min = min(x_min, xlims[0])
x_max = max(x_max, xlims[1])
# Don't display plot
plt.close(fig)
# Define width of histogram bins based on the x axis range
bin_width = (abs(math.floor(xlims[0])) + abs(math.ceil(xlims[1])))/20
# Setup figure with subplots
fig, axes = plt.subplots(
nrows=22,
ncols=6)
axes = axes.ravel()
count = 0
for h in hospital_names:
n_unique = df_hosp_shap_values[h].nunique()
ax=axes[count]
create_histogram_with_colours(df_hosp_shap_values[h],
np.arange(math.floor(xlims[0]),math.ceil(xlims[1]),bin_width),
ax)
ax.set_xlabel(f"SHAP value for {h} \n({n_unique} unique values)")
ax.set_ylabel("Number of instances")
ax.set_ylim(0, (y_max*1.1))
count += 1
# Define figure display
fig.set_figheight(50)
fig.set_figwidth(20)
#plt.tight_layout(pad=2)
fig.subplots_adjust(hspace=0.7, wspace=0.9)
plt.show()

One with just the instances that attend each hosptial
# Setup figure with subplots
fig, axes = plt.subplots(
nrows=22,
ncols=6)
axes = axes.ravel()
count = 0
for h in hospital_names:
mask = X_combined["Stroke team"] == h #drop "team_"
shap_values_not_attend = df_hosp_shap_values[h][mask]
n_unique = shap_values_not_attend.nunique()
ax=axes[count]
create_histogram_with_colours(shap_values_not_attend, 20, ax)
# ax.hist(shap_values_not_attend, bins=20)
ax.set_xlabel(f"SHAP value for {h} \n({n_unique} unique values)")
ax.set_ylabel("Number of instances \n(not attend hosptial)")
# ax.set_ylim(0, y_max)
# ax.set_xlim(x_min, x_max)
count += 1
fig.set_figheight(50)
fig.set_figwidth(20)
#plt.tight_layout(pad=2)
fig.subplots_adjust(hspace=0.7, wspace=0.9)
plt.show()
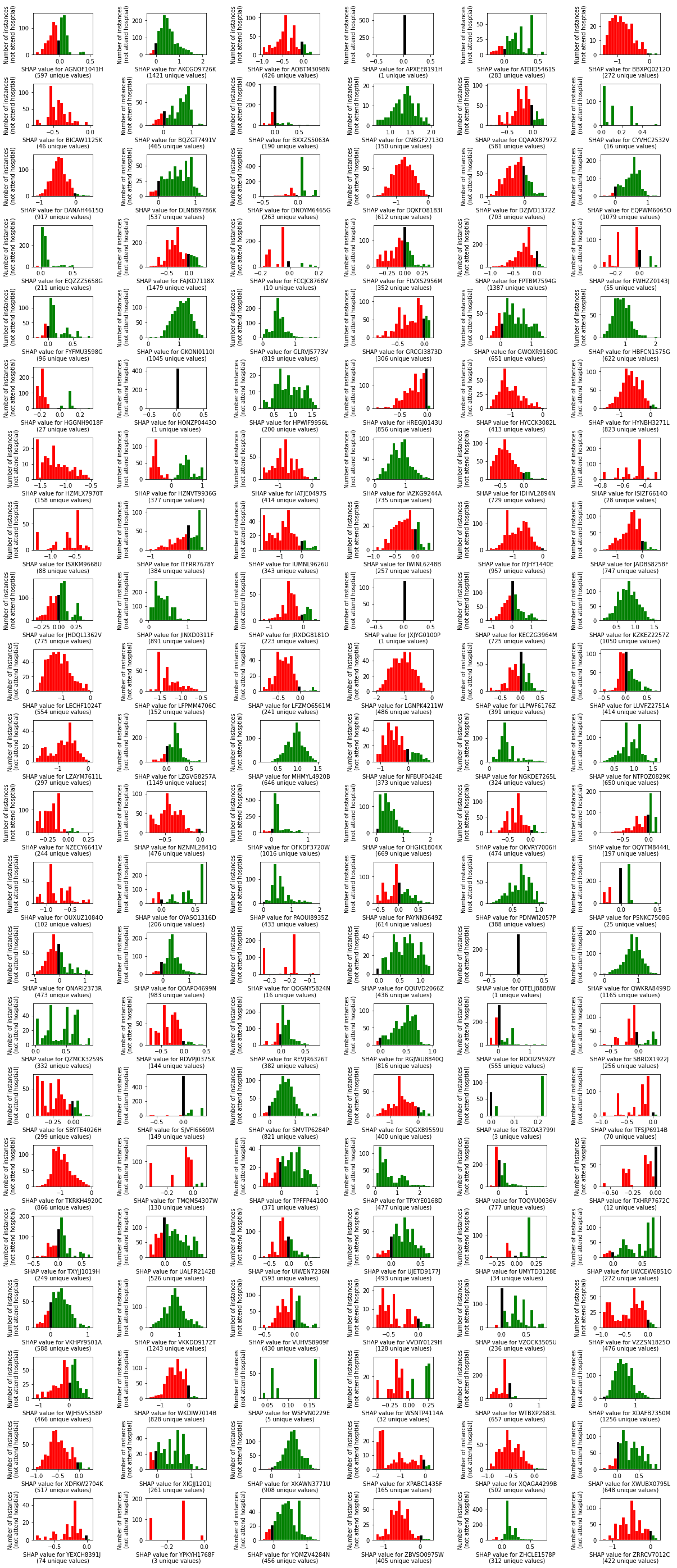
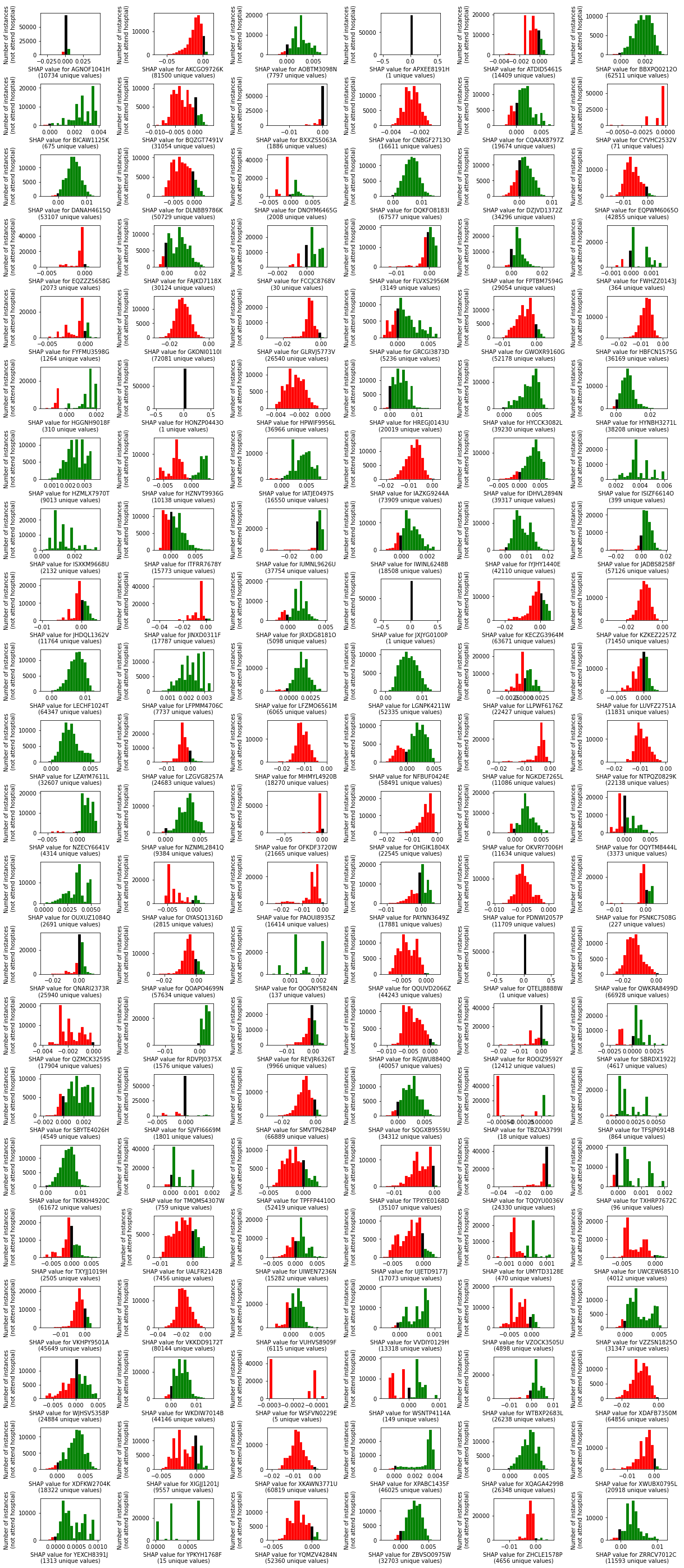
One with just the instances that don’t attend each hosptial.
# Setup figure with subplots
fig, axes = plt.subplots(
nrows=22,
ncols=6)
axes = axes.ravel()
count = 0
for h in hospital_names:
mask = X_combined["Stroke team"] == h #drop "team_"
mask = np.logical_not(mask)# Those that didn't attend
shap_values_not_attend = df_hosp_shap_values[h][mask]
n_unique = shap_values_not_attend.nunique()
ax=axes[count]
create_histogram_with_colours(shap_values_not_attend, 20, ax)
# ax.hist(shap_values_not_attend, bins=20)
ax.set_xlabel(f"SHAP value for {h} \n({n_unique} unique values)")
ax.set_ylabel("Number of instances \n(not attend hosptial)")
# ax.set_ylim(0, y_max)
# ax.set_xlim(x_min, x_max)
count += 1
fig.set_figheight(50)
fig.set_figwidth(20)
#plt.tight_layout(pad=2)
fig.subplots_adjust(hspace=0.7, wspace=0.9)
plt.show()
Code showing the same histograms, with each having the same x axis range and y axis range
# Find the largest value used for the y axis in all of the histograms in the
# subplots (use this to set the max for each subplot)
y_max = -1
x_min = 99
x_max = -99
fig, axes = plt.subplots(1)
for h in hospital_names:
# mask data for those that attend hospital
mask = df_hosp_shap_values["Stroke team"] == h
# Those that didn't attend
mask = np.logical_not(mask)
shap_values_attend = df_hosp_shap_values[h][mask]
n_unique = shap_values_attend.nunique()
# Plot histogram
axes.hist(shap_values_attend)
# Get axis limits
ylims = axes.get_ylim()
# Store if greater than found so far
y_max = max(y_max, ylims[1])
# Get axis limits
xlims = axes.get_xlim()
# Store if greater than found so far
x_min = min(x_min, xlims[0])
x_max = max(x_max, xlims[1])
# Don't display plot
plt.close(fig)
# Define width of histogram bins based on the x axis range
bin_width = (abs(math.floor(xlims[0])) + abs(math.ceil(xlims[1])))/20
# Setup figure with subplots
fig, axes = plt.subplots(
nrows=22,
ncols=6)
axes = axes.ravel()
count = 0
for h in hospital_names:
# mask data for those that attend hospital
mask = df_hosp_shap_values["Stroke team"] == h
# Those that didn't attend
mask = np.logical_not(mask)
shap_values_attend = df_hosp_shap_values[h][mask]
n_unique = shap_values_attend.nunique()
# Plot histogram
ax=axes[count]
ax.hist(shap_values_attend,
bins=np.arange(math.floor(xlims[0]),math.ceil(xlims[1]),bin_width))
ax.set_xlabel(f"SHAP value for {h} \n({n_unique} unique values)")
ax.set_ylabel("Number of instances")
ax.set_ylim(0, (y_max*1.1))
count += 1
# Define figure display
fig.set_figheight(50)
fig.set_figwidth(20)
#plt.tight_layout(pad=2)
fig.subplots_adjust(hspace=0.7, wspace=0.9)
plt.show()
