Predicting differences between local and benchmark decisions
Contents
Predicting differences between local and benchmark decisions#
This experiment focuses on hospitals who would give thrombolysis to at least 50% more patients if the majority vote of 30 benchmark hospitals were applied. We build a model to predict those patients, out of patients who will be thrombolysed by the majority of the benchmark hospitals, who will thrombolysed at a local unit. The XGBoost model used to make predictions uses 8 features:
S2BrainImagingTime_min
S2StrokeType_Infarction
S2NihssArrival
S1OnsetTimeType_Precise
S2RankinBeforeStroke
StrokeTeam
AFAnticoagulent_Yes
S1OnsetToArrival_min
Aims:
Of all those patients thrombolysed by benchmark decision, build an XGBoost model to predict which patients, would be thrombolysed at a local unit.
Investigate model predictions using Shap
# Turn warnings off to keep notebook tidy
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pickle
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import auc
from sklearn.metrics import roc_curve
from xgboost import XGBClassifier
import shap
Function to calculate accuracy measures#
def calculate_accuracy(observed, predicted):
"""
Calculates a range of accuracy scores from observed and predicted classes.
Takes two list or NumPy arrays (observed class values, and predicted class
values), and returns a dictionary of results.
1) observed positive rate: proportion of observed cases that are +ve
2) Predicted positive rate: proportion of predicted cases that are +ve
3) observed negative rate: proportion of observed cases that are -ve
4) Predicted negative rate: proportion of predicted cases that are -ve
5) accuracy: proportion of predicted results that are correct
6) precision: proportion of predicted +ve that are correct
7) recall: proportion of true +ve correctly identified
8) f1: harmonic mean of precision and recall
9) sensitivity: Same as recall
10) specificity: Proportion of true -ve identified:
11) positive likelihood: increased probability of true +ve if test +ve
12) negative likelihood: reduced probability of true +ve if test -ve
13) false positive rate: proportion of false +ves in true -ve patients
14) false negative rate: proportion of false -ves in true +ve patients
15) true positive rate: Same as recall
16) true negative rate: Same as specificity
17) positive predictive value: chance of true +ve if test +ve
18) negative predictive value: chance of true -ve if test -ve
"""
# Converts list to NumPy arrays
if type(observed) == list:
observed = np.array(observed)
if type(predicted) == list:
predicted = np.array(predicted)
# Calculate accuracy scores
observed_positives = observed == 1
observed_negatives = observed == 0
predicted_positives = predicted == 1
predicted_negatives = predicted == 0
true_positives = (predicted_positives == 1) & (observed_positives == 1)
false_positives = (predicted_positives == 1) & (observed_positives == 0)
true_negatives = (predicted_negatives == 1) & (observed_negatives == 1)
false_negatives = (predicted_negatives == 1) & (observed_negatives == 0)
accuracy = np.mean(predicted == observed)
precision = (np.sum(true_positives) /
(np.sum(true_positives) + np.sum(false_positives)))
recall = np.sum(true_positives) / np.sum(observed_positives)
sensitivity = recall
f1 = 2 * ((precision * recall) / (precision + recall))
specificity = np.sum(true_negatives) / np.sum(observed_negatives)
positive_likelihood = sensitivity / (1 - specificity)
negative_likelihood = (1 - sensitivity) / specificity
false_positive_rate = 1 - specificity
false_negative_rate = 1 - sensitivity
true_positive_rate = sensitivity
true_negative_rate = specificity
positive_predictive_value = (np.sum(true_positives) /
(np.sum(true_positives) + np.sum(false_positives)))
negative_predictive_value = (np.sum(true_negatives) /
(np.sum(true_negatives) + np.sum(false_negatives)))
# Create dictionary for results, and add results
results = dict()
results['observed_positive_rate'] = np.mean(observed_positives)
results['observed_negative_rate'] = np.mean(observed_negatives)
results['predicted_positive_rate'] = np.mean(predicted_positives)
results['predicted_negative_rate'] = np.mean(predicted_negatives)
results['accuracy'] = accuracy
results['precision'] = precision
results['recall'] = recall
results['f1'] = f1
results['sensitivity'] = sensitivity
results['specificity'] = specificity
results['positive_likelihood'] = positive_likelihood
results['negative_likelihood'] = negative_likelihood
results['false_positive_rate'] = false_positive_rate
results['false_negative_rate'] = false_negative_rate
results['true_positive_rate'] = true_positive_rate
results['true_negative_rate'] = true_negative_rate
results['positive_predictive_value'] = positive_predictive_value
results['negative_predictive_value'] = negative_predictive_value
return results
Load data#
thrombolysis_decision_data = pd.read_csv(
'./predictions/benchmark_decisions_combined_xgb_key_features.csv')
Add label where benchmark = 1, but observed = 0
thrombolysis_decision_data['benchmark_yes_observed_no'] = (
(thrombolysis_decision_data['majority_vote'] == 1) &
(thrombolysis_decision_data['observed'] == 0))
thrombolysis_decision_data
| unit | observed | predicted_thrombolysis | predicted_proba | majority_vote | benchmark_yes_observed_no | |
|---|---|---|---|---|---|---|
| 0 | TXHRP7672C | 1 | 1.0 | 0.880155 | 1.0 | False |
| 1 | SQGXB9559U | 1 | 1.0 | 0.627783 | 1.0 | False |
| 2 | LFPMM4706C | 0 | 0.0 | 0.042199 | 0.0 | False |
| 3 | MHMYL4920B | 0 | 0.0 | 0.000084 | 0.0 | False |
| 4 | EQZZZ5658G | 1 | 1.0 | 0.916311 | 1.0 | False |
| ... | ... | ... | ... | ... | ... | ... |
| 88787 | OYASQ1316D | 1 | 1.0 | 0.917107 | 1.0 | False |
| 88788 | SMVTP6284P | 0 | 0.0 | 0.023144 | 0.0 | False |
| 88789 | RDVPJ0375X | 0 | 0.0 | 0.089444 | 0.0 | False |
| 88790 | FAJKD7118X | 0 | 1.0 | 0.615767 | 1.0 | True |
| 88791 | QWKRA8499D | 0 | 0.0 | 0.160670 | 0.0 | False |
88792 rows × 6 columns
Combine with feature data for patients.
feature_data = pd.read_csv(
'./predictions/test_features_collated_key_features.csv')
feature_data['benchmark_yes_observed_no'] = \
thrombolysis_decision_data['benchmark_yes_observed_no'] * 1
feature_data['majority_vote'] = \
thrombolysis_decision_data['majority_vote'] * 1
feature_data['predicted_thrombolysis'] = \
thrombolysis_decision_data['predicted_thrombolysis']
feature_data['observed'] = thrombolysis_decision_data['observed']
feature_data
| S2BrainImagingTime_min | S2StrokeType_Infarction | S2NihssArrival | S1OnsetTimeType_Precise | S2RankinBeforeStroke | StrokeTeam | AFAnticoagulent_Yes | S1OnsetToArrival_min | S2Thrombolysis | benchmark_yes_observed_no | majority_vote | predicted_thrombolysis | observed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.0 | 1 | 14.0 | 1 | 0 | TXHRP7672C | 0 | 186.0 | 1 | 0 | 1.0 | 1.0 | 1 |
| 1 | 25.0 | 1 | 6.0 | 1 | 0 | SQGXB9559U | 0 | 71.0 | 1 | 0 | 1.0 | 1.0 | 1 |
| 2 | 138.0 | 1 | 2.0 | 1 | 0 | LFPMM4706C | 0 | 67.0 | 0 | 0 | 0.0 | 0.0 | 0 |
| 3 | 21.0 | 0 | 11.0 | 1 | 0 | MHMYL4920B | 0 | 86.0 | 0 | 0 | 0.0 | 0.0 | 0 |
| 4 | 8.0 | 1 | 16.0 | 1 | 0 | EQZZZ5658G | 0 | 83.0 | 1 | 0 | 1.0 | 1.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 88787 | 3.0 | 1 | 11.0 | 1 | 1 | OYASQ1316D | 0 | 140.0 | 1 | 0 | 1.0 | 1.0 | 1 |
| 88788 | 69.0 | 1 | 3.0 | 0 | 4 | SMVTP6284P | 0 | 189.0 | 0 | 0 | 0.0 | 0.0 | 0 |
| 88789 | 63.0 | 1 | 3.0 | 1 | 1 | RDVPJ0375X | 0 | 154.0 | 0 | 0 | 0.0 | 0.0 | 0 |
| 88790 | 14.0 | 1 | 4.0 | 1 | 0 | FAJKD7118X | 0 | 77.0 | 0 | 1 | 1.0 | 1.0 | 0 |
| 88791 | 41.0 | 1 | 1.0 | 1 | 1 | QWKRA8499D | 0 | 77.0 | 0 | 0 | 0.0 | 0.0 | 0 |
88792 rows × 13 columns
Identify hospitals where benchmark decision would lead to at least 50% higher thrombolysis#
thrombolysis_counts = (thrombolysis_decision_data.groupby('unit').agg('sum').drop(
'predicted_proba', axis=1))
thrombolysis_counts['benchmark_ratio'] = \
thrombolysis_counts['majority_vote'] / thrombolysis_counts['observed']
mask = thrombolysis_counts['benchmark_ratio'] >= 1.5
low_thrombolysing_hospitals_df = thrombolysis_counts[mask]
low_thrombolysing_hospitals_df.sort_values(
'benchmark_ratio', inplace=True, ascending=False)
low_thrombolysing_hospitals = list(low_thrombolysing_hospitals_df.index)
low_thrombolysing_hospitals_df.head()
| observed | predicted_thrombolysis | majority_vote | benchmark_yes_observed_no | benchmark_ratio | |
|---|---|---|---|---|---|
| unit | |||||
| HZMLX7970T | 34 | 28.0 | 80.0 | 49 | 2.352941 |
| LFPMM4706C | 21 | 7.0 | 46.0 | 29 | 2.190476 |
| LZAYM7611L | 40 | 23.0 | 86.0 | 55 | 2.150000 |
| XPABC1435F | 36 | 39.0 | 76.0 | 41 | 2.111111 |
| LECHF1024T | 114 | 110.0 | 230.0 | 128 | 2.017544 |
Build a model to distinguish between local and top30 thrombolysis#
# Restrict data to low thrombolysing hospitals and benchmark = yes and observed = no
mask = feature_data['StrokeTeam'].isin(low_thrombolysing_hospitals)
restricted_data = feature_data[mask]
# Get only patients thrombolysed in top 30
mask = restricted_data['majority_vote'] == 1
restricted_data = restricted_data[mask]
cols_to_drop = ['benchmark_yes_observed_no', 'predicted_thrombolysis',
'majority_vote','observed']
restricted_data.drop(cols_to_drop, axis=1, inplace=True)
restricted_data
| S2BrainImagingTime_min | S2StrokeType_Infarction | S2NihssArrival | S1OnsetTimeType_Precise | S2RankinBeforeStroke | StrokeTeam | AFAnticoagulent_Yes | S1OnsetToArrival_min | S2Thrombolysis | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 25.0 | 1 | 6.0 | 1 | 0 | SQGXB9559U | 0 | 71.0 | 1 |
| 28 | 38.0 | 1 | 13.0 | 1 | 0 | DQKFO8183I | 0 | 149.0 | 1 |
| 91 | 18.0 | 1 | 15.0 | 1 | 0 | OUXUZ1084Q | 0 | 122.0 | 0 |
| 159 | 2.0 | 1 | 16.0 | 1 | 2 | IATJE0497S | 0 | 78.0 | 1 |
| 161 | 8.0 | 1 | 4.0 | 1 | 0 | DANAH4615Q | 0 | 160.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 88667 | 66.0 | 1 | 16.0 | 1 | 0 | LGNPK4211W | 0 | 46.0 | 0 |
| 88698 | 5.0 | 1 | 16.0 | 1 | 2 | ISIZF6614O | 0 | 109.0 | 1 |
| 88740 | 10.0 | 1 | 5.0 | 1 | 0 | NFBUF0424E | 0 | 67.0 | 0 |
| 88758 | 9.0 | 1 | 3.0 | 1 | 0 | ISIZF6614O | 0 | 89.0 | 0 |
| 88783 | 19.0 | 1 | 14.0 | 1 | 0 | SQGXB9559U | 0 | 119.0 | 1 |
4788 rows × 9 columns
Set up X, Y and train/test split.
X = restricted_data.drop('S2Thrombolysis', axis=1)
y = restricted_data['S2Thrombolysis']
# Remove hospital ID
X.drop('StrokeTeam', axis=1, inplace=True)
skf = StratifiedKFold(n_splits = 5, random_state=42, shuffle=True)
skf.get_n_splits(X, y)
# Set up list to store models
model_kfold = []
# Set up lists for k-fold fits
observed_kfold = []
predicted_proba_kfold = []
predicted_kfold = []
X_train_kfold = []
X_test_kfold = []
y_train_kfold = []
y_test_kfold = []
# Set up list for feature importances
importances_kfold = []
# Loop through the k-fold splits
k_fold = 0
for train_index, test_index in skf.split(X, y):
k_fold += 1
# Get X and Y train/test
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
X_train_kfold.append(X_train)
X_test_kfold.append(X_test)
y_train_kfold.append(y_train)
y_test_kfold.append(y_test)
# Define model
model = XGBClassifier(
verbosity = 0,
scale_pos_weight=0.8,
random_state=42,
learning_rate=0.1)
# Fit model
model.fit(X_train, y_train)
model_kfold.append(model)
# Get predicted probabilities
y_probs = model.predict_proba(X_test)[:,1]
predicted_proba_kfold.append(y_probs)
observed_kfold.append(y_test)
# Get feature importances
importance = model.feature_importances_
importances_kfold.append(importance)
# Get class
true_rate = np.mean(y_test)
y_class = y_probs >= 0.5
y_class = np.array(y_class) * 1.0
predicted_kfold.append(y_class)
# Print accuracy
accuracy = np.mean(y_class == y_test)
print (
f'Run {k_fold}, accuracy: {accuracy:0.3f}')
Run 1, accuracy: 0.658
Run 2, accuracy: 0.691
Run 3, accuracy: 0.696
Run 4, accuracy: 0.671
Run 5, accuracy: 0.662
Accuracy measures#
# Set up list for results
k_fold_results = []
# Loop through k fold predictions and get accuracy measures
for i in range(5):
results = calculate_accuracy(observed_kfold[i], predicted_kfold[i])
k_fold_results.append(results)
# Put results in DataFrame
accuracy_results = pd.DataFrame(k_fold_results).T
accuracy_results
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| observed_positive_rate | 0.530271 | 0.530271 | 0.530271 | 0.530825 | 0.529781 |
| observed_negative_rate | 0.469729 | 0.469729 | 0.469729 | 0.469175 | 0.470219 |
| predicted_positive_rate | 0.492693 | 0.534447 | 0.518789 | 0.502612 | 0.493208 |
| predicted_negative_rate | 0.507307 | 0.465553 | 0.481211 | 0.497388 | 0.506792 |
| accuracy | 0.657620 | 0.691023 | 0.696242 | 0.670846 | 0.662487 |
| precision | 0.690678 | 0.707031 | 0.718310 | 0.700624 | 0.694915 |
| recall | 0.641732 | 0.712598 | 0.702756 | 0.663386 | 0.646943 |
| f1 | 0.665306 | 0.709804 | 0.710448 | 0.681496 | 0.670072 |
| sensitivity | 0.641732 | 0.712598 | 0.702756 | 0.663386 | 0.646943 |
| specificity | 0.675556 | 0.666667 | 0.688889 | 0.679287 | 0.680000 |
| positive_likelihood | 1.977942 | 2.137795 | 2.258858 | 2.068474 | 2.021696 |
| negative_likelihood | 0.530331 | 0.431102 | 0.431483 | 0.495540 | 0.519202 |
| false_positive_rate | 0.324444 | 0.333333 | 0.311111 | 0.320713 | 0.320000 |
| false_negative_rate | 0.358268 | 0.287402 | 0.297244 | 0.336614 | 0.353057 |
| true_positive_rate | 0.641732 | 0.712598 | 0.702756 | 0.663386 | 0.646943 |
| true_negative_rate | 0.675556 | 0.666667 | 0.688889 | 0.679287 | 0.680000 |
| positive_predictive_value | 0.690678 | 0.707031 | 0.718310 | 0.700624 | 0.694915 |
| negative_predictive_value | 0.625514 | 0.672646 | 0.672451 | 0.640756 | 0.630928 |
accuracy_results.T.describe()
| observed_positive_rate | observed_negative_rate | predicted_positive_rate | predicted_negative_rate | accuracy | precision | recall | f1 | sensitivity | specificity | positive_likelihood | negative_likelihood | false_positive_rate | false_negative_rate | true_positive_rate | true_negative_rate | positive_predictive_value | negative_predictive_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 |
| mean | 0.530284 | 0.469716 | 0.508350 | 0.491650 | 0.675644 | 0.702312 | 0.673483 | 0.687425 | 0.673483 | 0.678080 | 2.092953 | 0.481532 | 0.321920 | 0.326517 | 0.673483 | 0.678080 | 0.702312 | 0.648459 |
| std | 0.000370 | 0.000370 | 0.018009 | 0.018009 | 0.017189 | 0.010853 | 0.032409 | 0.021543 | 0.032409 | 0.008041 | 0.110045 | 0.047551 | 0.008041 | 0.032409 | 0.032409 | 0.008041 | 0.010853 | 0.022659 |
| min | 0.529781 | 0.469175 | 0.492693 | 0.465553 | 0.657620 | 0.690678 | 0.641732 | 0.665306 | 0.641732 | 0.666667 | 1.977942 | 0.431102 | 0.311111 | 0.287402 | 0.641732 | 0.666667 | 0.690678 | 0.625514 |
| 25% | 0.530271 | 0.469729 | 0.493208 | 0.481211 | 0.662487 | 0.694915 | 0.646943 | 0.670072 | 0.646943 | 0.675556 | 2.021696 | 0.431483 | 0.320000 | 0.297244 | 0.646943 | 0.675556 | 0.694915 | 0.630928 |
| 50% | 0.530271 | 0.469729 | 0.502612 | 0.497388 | 0.670846 | 0.700624 | 0.663386 | 0.681496 | 0.663386 | 0.679287 | 2.068474 | 0.495540 | 0.320713 | 0.336614 | 0.663386 | 0.679287 | 0.700624 | 0.640756 |
| 75% | 0.530271 | 0.469729 | 0.518789 | 0.506792 | 0.691023 | 0.707031 | 0.702756 | 0.709804 | 0.702756 | 0.680000 | 2.137795 | 0.519202 | 0.324444 | 0.353057 | 0.702756 | 0.680000 | 0.707031 | 0.672451 |
| max | 0.530825 | 0.470219 | 0.534447 | 0.507307 | 0.696242 | 0.718310 | 0.712598 | 0.710448 | 0.712598 | 0.688889 | 2.258858 | 0.530331 | 0.333333 | 0.358268 | 0.712598 | 0.688889 | 0.718310 | 0.672646 |
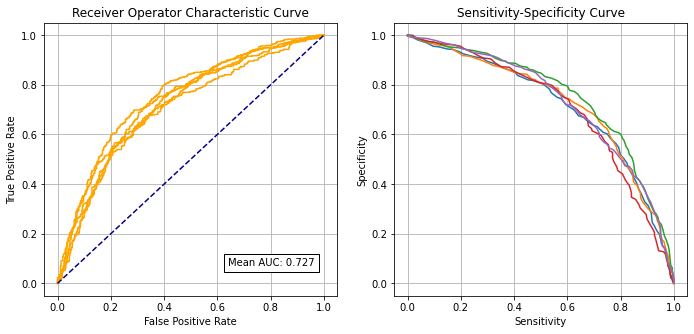
Receiver Operator Characteristic and Sensitivity-Specificity Curves#
Receiver Operator Characteristic Curve:
# Set up lists for results
k_fold_fpr = [] # false positive rate
k_fold_tpr = [] # true positive rate
k_fold_thresholds = [] # threshold applied
k_fold_auc = [] # area under curve
# Loop through k fold predictions and get ROC results
for i in range(5):
fpr, tpr, thresholds = roc_curve(
observed_kfold[i], predicted_proba_kfold[i])
roc_auc = auc(fpr, tpr)
k_fold_fpr.append(fpr)
k_fold_tpr.append(tpr)
k_fold_thresholds.append(thresholds)
k_fold_auc.append(roc_auc)
# Show mean area under curve
mean_auc = np.mean(k_fold_auc)
sd_auc = np.std(k_fold_auc)
print (f'\nMean AUC: {mean_auc:0.4f}')
print (f'SD AUC: {sd_auc:0.4f}')
Mean AUC: 0.7271
SD AUC: 0.0158
Sensitivity-specificity curve:
k_fold_sensitivity = []
k_fold_specificity = []
for i in range(5):
# Get classificiation probabilities for k-fold replicate
obs = observed_kfold[i]
proba = predicted_proba_kfold[i]
# Set up list for accuracy measures
sensitivity = []
specificity = []
# Loop through increments in probability of survival
thresholds = np.arange(0.0, 1.01, 0.01)
for cutoff in thresholds: # loop 0 --> 1 on steps of 0.1
# Get classificiation using cutoff
predicted_class = proba >= cutoff
predicted_class = predicted_class * 1.0
# Call accuracy measures function
accuracy = calculate_accuracy(obs, predicted_class)
# Add accuracy scores to lists
sensitivity.append(accuracy['sensitivity'])
specificity.append(accuracy['specificity'])
# Add replicate to lists
k_fold_sensitivity.append(sensitivity)
k_fold_specificity.append(specificity)
Combined plot:
fig = plt.figure(figsize=(10,5))
# Plot ROC
ax1 = fig.add_subplot(121)
for i in range(5):
ax1.plot(k_fold_fpr[i], k_fold_tpr[i], color='orange')
ax1.plot([0, 1], [0, 1], color='darkblue', linestyle='--')
ax1.set_xlabel('False Positive Rate')
ax1.set_ylabel('True Positive Rate')
ax1.set_title('Receiver Operator Characteristic Curve')
text = f'Mean AUC: {mean_auc:.3f}'
ax1.text(0.64,0.07, text,
bbox=dict(facecolor='white', edgecolor='black'))
plt.grid(True)
# Plot sensitivity-specificity
ax2 = fig.add_subplot(122)
for i in range(5):
ax2.plot(k_fold_sensitivity[i], k_fold_specificity[i])
ax2.set_xlabel('Sensitivity')
ax2.set_ylabel('Specificity')
ax2.set_title('Sensitivity-Specificity Curve')
plt.grid(True)
plt.tight_layout(pad=2)
plt.savefig('./output/decision_comparison_roc_sens_spec_key_features.jpg', dpi=300)
plt.show()
Identify cross-over of sensitivity and specificity#
def get_intersect(a1, a2, b1, b2):
"""
Returns the point of intersection of the lines passing through a2,a1 and b2,b1.
a1: [x, y] a point on the first line
a2: [x, y] another point on the first line
b1: [x, y] a point on the second line
b2: [x, y] another point on the second line
"""
s = np.vstack([a1,a2,b1,b2]) # s for stacked
h = np.hstack((s, np.ones((4, 1)))) # h for homogeneous
l1 = np.cross(h[0], h[1]) # get first line
l2 = np.cross(h[2], h[3]) # get second line
x, y, z = np.cross(l1, l2) # point of intersection
if z == 0: # lines are parallel
return (float('inf'), float('inf'))
return (x/z, y/z)
intersections = []
for i in range(5):
sens = np.array(k_fold_sensitivity[i])
spec = np.array(k_fold_specificity[i])
df = pd.DataFrame()
df['sensitivity'] = sens
df['specificity'] = spec
df['spec greater sens'] = spec > sens
# find last index for senitivity being greater than specificity
mask = df['spec greater sens'] == False
last_id_sens_greater_spec = np.max(df[mask].index)
locs = [last_id_sens_greater_spec, last_id_sens_greater_spec + 1]
points = df.iloc[locs][['sensitivity', 'specificity']]
# Get intersetction with line of x=y
a1 = list(points.iloc[0].values)
a2 = list(points.iloc[1].values)
b1 = [0, 0]
b2 = [1, 1]
intersections.append(get_intersect(a1, a2, b1, b2)[0])
mean_intersection = np.mean(intersections)
sd_intersection = np.std(intersections)
print (f'\nMean intersection: {mean_intersection:0.4f}')
print (f'SD intersection: {sd_intersection:0.4f}')
Mean intersection: 0.6772
SD intersection: 0.0133
Shap values#
We will look into detailed Shap values for the first train/test split.
Get Shap values#
k_fold_shap_values_extended = []
k_fold_shap_values = []
for k in range(5):
# Set up explainer using typical feature values from training set
explainer = shap.TreeExplainer(model_kfold[k], X_train_kfold[k])
# Get Shapley values along with base and features
shap_values_extended = explainer(X_test_kfold[k])
k_fold_shap_values_extended.append(shap_values_extended)
# Shap values exist for each classification in a Tree; 1=give thrombolysis
shap_values = shap_values_extended.values
k_fold_shap_values.append(shap_values)
print (f'Completed {k+1} of 5')
Completed 1 of 5
Completed 2 of 5
Completed 3 of 5
Completed 4 of 5
Completed 5 of 5
Get average Shap values for each k-fold#
shap_values_mean_kfold = []
features = list(X_train_kfold[0])
for k in range(5):
shap_values = k_fold_shap_values[k]
# Get mean Shap values for each feature
shap_values_mean = pd.DataFrame(index=features)
shap_values_mean['mean_shap'] = np.mean(shap_values, axis=0)
shap_values_mean['abs_mean_shap'] = np.abs(shap_values_mean)
shap_values_mean['mean_abs_shap'] = np.mean(np.abs(shap_values), axis=0)
shap_values_mean['rank'] = shap_values_mean['mean_abs_shap'].rank(
ascending=False).values
shap_values_mean.sort_index()
shap_values_mean_kfold.append(shap_values_mean)
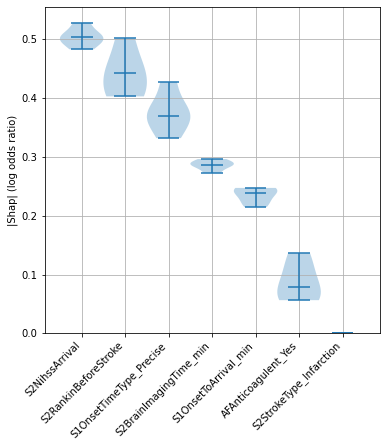
Examine consistency across top Shap values (mean |Shap|)#
‘Raw’ Shap values from XGBoost model are log odds ratios.
# Build df for k fold values
mean_abs_shap = pd.DataFrame()
for k in range(5):
mean_abs_shap[f'{k}'] = shap_values_mean_kfold[k]['mean_abs_shap']
# Build df to show min, median, and max
mean_abs_shap_summary = pd.DataFrame()
mean_abs_shap_summary['min'] = mean_abs_shap.min(axis=1)
mean_abs_shap_summary['median'] = mean_abs_shap.median(axis=1)
mean_abs_shap_summary['max'] = mean_abs_shap.max(axis=1)
mean_abs_shap_summary.sort_values('median', inplace=True, ascending=False)
top_10_shap = list(mean_abs_shap_summary.head(10).index)
fig = plt.figure(figsize=(6,6))
ax1 = fig.add_subplot(111)
ax1.violinplot(mean_abs_shap.loc[top_10_shap].T,
showmedians=True,
widths=1)
ax1.set_ylim(0)
labels = top_10_shap
ax1.set_xticks(np.arange(1, len(labels) + 1))
ax1.set_xticklabels(labels, rotation=45, ha='right')
ax1.grid(which='both')
ax1.set_ylabel('|Shap| (log odds ratio)')
plt.savefig('output/decision_comparison_shap_violin_key_features.jpg', dpi=300)
plt.show()
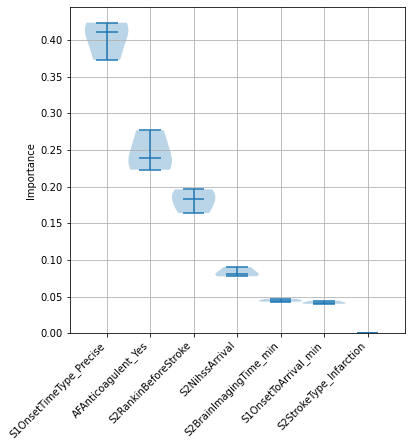
Examine consitency of feature importances#
# Build df for k fold values
importances_df = pd.DataFrame()
for k in range(5):
importances_df[f'{k}'] = importances_kfold[k]
# Build df to show min, median, and max
importances_summary = pd.DataFrame()
importances_summary['min'] = importances_df.min(axis=1)
importances_summary['median'] = importances_df.median(axis=1)
importances_summary['max'] = importances_df.max(axis=1)
importances_summary.sort_values('median', inplace=True, ascending=False)
importance_features_index = list(importances_summary.index)
# Add feature names back in
importances_summary['feature'] = \
[list(X_train)[feat] for feat in importance_features_index]
importances_summary.set_index('feature', inplace=True)
importances_summary
| min | median | max | |
|---|---|---|---|
| feature | |||
| S1OnsetTimeType_Precise | 0.372726 | 0.410977 | 0.423405 |
| AFAnticoagulent_Yes | 0.223079 | 0.238576 | 0.276714 |
| S2RankinBeforeStroke | 0.163903 | 0.183379 | 0.196325 |
| S2NihssArrival | 0.077793 | 0.081011 | 0.090417 |
| S2BrainImagingTime_min | 0.043173 | 0.044716 | 0.047084 |
| S1OnsetToArrival_min | 0.040286 | 0.041661 | 0.044221 |
| S2StrokeType_Infarction | 0.000000 | 0.000000 | 0.000000 |
top_10_importances = list(importances_summary.head(10).index)
fig = plt.figure(figsize=(6,6))
ax1 = fig.add_subplot(111)
ax1.violinplot(importances_summary.loc[top_10_importances].T,
showmedians=True,
widths=1)
ax1.set_ylim(0)
labels = top_10_importances
ax1.set_xticks(np.arange(1, len(labels) + 1))
ax1.set_xticklabels(labels, rotation=45, ha='right')
ax1.grid(which='both')
ax1.set_ylabel('Importance')
plt.savefig('output/decision_comparison_importance_violin_key_features.jpg', dpi=300)
plt.show()
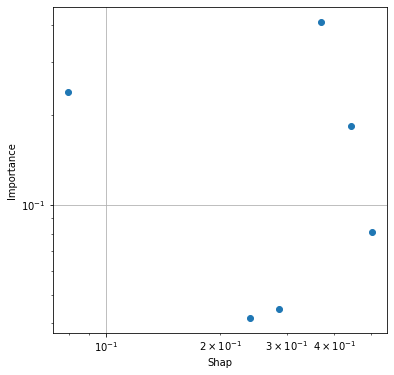
Compare top 10 Shap and importances#
compare_shap_importance = pd.DataFrame()
compare_shap_importance['Shap'] = mean_abs_shap_summary.head(10).index
compare_shap_importance['Importance'] = importances_summary.head(10).index
compare_shap_importance
| Shap | Importance | |
|---|---|---|
| 0 | S2NihssArrival | S1OnsetTimeType_Precise |
| 1 | S2RankinBeforeStroke | AFAnticoagulent_Yes |
| 2 | S1OnsetTimeType_Precise | S2RankinBeforeStroke |
| 3 | S2BrainImagingTime_min | S2NihssArrival |
| 4 | S1OnsetToArrival_min | S2BrainImagingTime_min |
| 5 | AFAnticoagulent_Yes | S1OnsetToArrival_min |
| 6 | S2StrokeType_Infarction | S2StrokeType_Infarction |
shap_importance = pd.DataFrame()
shap_importance['Shap'] = mean_abs_shap_summary['median']
shap_importance = shap_importance.merge(
importances_summary['median'], left_index=True, right_index=True)
shap_importance.rename(columns={'median':'Importance'}, inplace=True)
shap_importance.sort_values('Shap', inplace=True, ascending=False)
shap_importance.head(10)
| Shap | Importance | |
|---|---|---|
| S2NihssArrival | 0.503784 | 0.081011 |
| S2RankinBeforeStroke | 0.443493 | 0.183379 |
| S1OnsetTimeType_Precise | 0.369657 | 0.410977 |
| S2BrainImagingTime_min | 0.286047 | 0.044716 |
| S1OnsetToArrival_min | 0.239312 | 0.041661 |
| AFAnticoagulent_Yes | 0.079252 | 0.238576 |
| S2StrokeType_Infarction | 0.000000 | 0.000000 |
fig = plt.figure(figsize=(6,6))
ax1 = fig.add_subplot(111)
ax1.scatter(shap_importance['Shap'],
shap_importance['Importance'])
ax1.set_xscale('log')
ax1.set_yscale('log')
ax1.set_xlabel('Shap')
ax1.set_ylabel('Importance')
ax1.grid()
plt.savefig(
'output/decision_comparison_shap_importance_correlation_key_features.jpg',
dpi=300)
plt.show()
Further analysis of one k-fold#
Having established that Shap values have good consistency across k-fold replictaes, here we show more detail on Shap using the first k_fold replicate.
# Get all key values from first k fold
model = model_kfold[0]
shap_values = k_fold_shap_values[0]
shap_values_extended = k_fold_shap_values_extended[0]
importances = importances_kfold[0]
y_pred = predicted_kfold[0]
y_prob = predicted_proba_kfold[0]
X_train = X_train_kfold[0]
X_test = X_test_kfold[0]
y_train = y_train_kfold[0]
y_test = y_test_kfold[0]
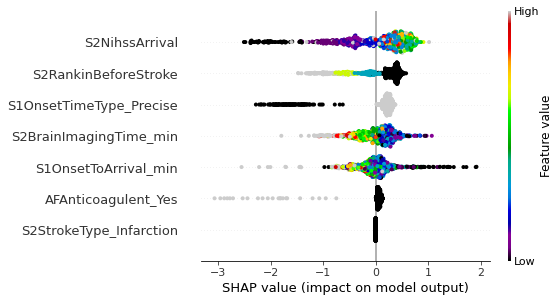
Beeswarm plot#
A Beeswarm plot shows all points. The feature value for each point is shown by the colour, and its position indicates the Shap value for that instance.
fig = plt.figure(figsize=(6,6))
shap.summary_plot(shap_values=shap_values,
features=X_test,
feature_names=features,
max_display=8,
cmap=plt.get_cmap('nipy_spectral'), show=False)
plt.savefig('output/xgb_decision_comparison_beeswarm_key_features.jpg',
dpi=300, bbox_inches='tight', pad_inches=0.2)
plt.show()
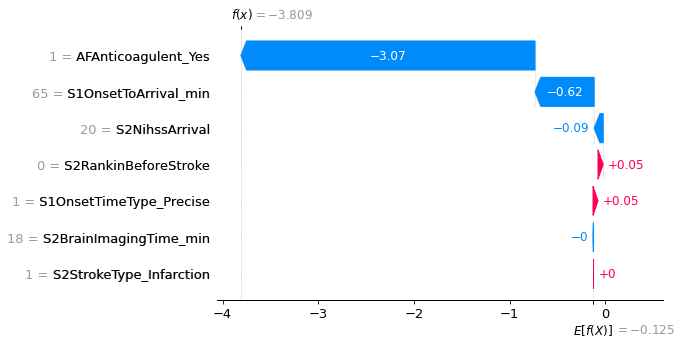
Plot Waterfall and decision plot plots for instances with low or high probability of receiving thrombolysis#
Waterfall plot and decision plots are alternative ways of plotting the influence of features for individual cases.
# Get the location of an example each of low and high probablility
location_low_probability = np.where(y_prob == np.min(y_prob))[0][0]
location_high_probability = np.where(y_prob == np.max(y_prob))[0][0]
An example with low probability of receiving thrombolysis.
fig = shap.plots.waterfall(shap_values_extended[location_low_probability],
show=False, max_display=8)
plt.savefig('output/xgb_decision_comparison_waterfall_low_key_features.jpg',
dpi=300, bbox_inches='tight', pad_inches=0.2)
plt.show()
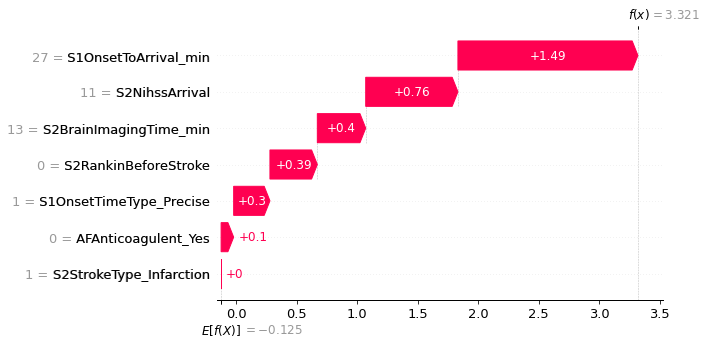
An example with high probability of receiving thrombolysis.
fig = shap.plots.waterfall(shap_values_extended[location_high_probability],
show=False, max_display=8)
plt.savefig('output/xgb_decision_comparison_waterfall_high_key_features.jpg',
dpi=300, bbox_inches='tight', pad_inches=0.2)
plt.show()
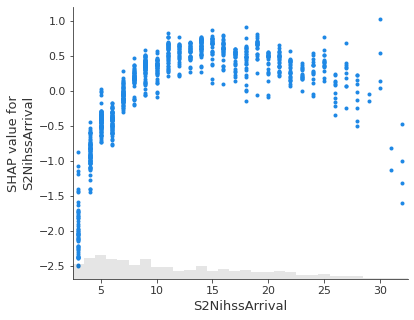
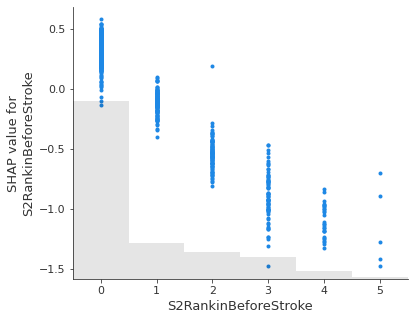
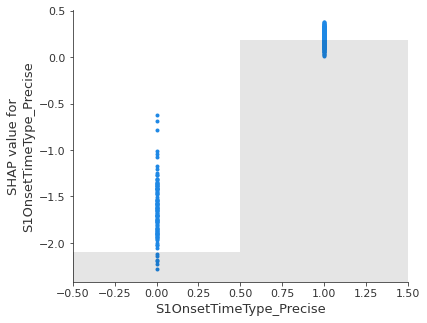
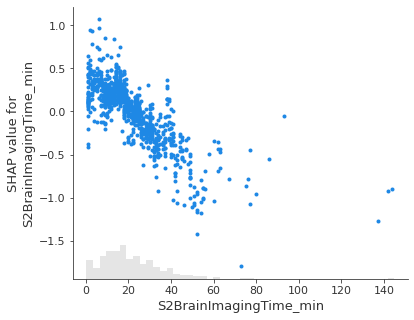
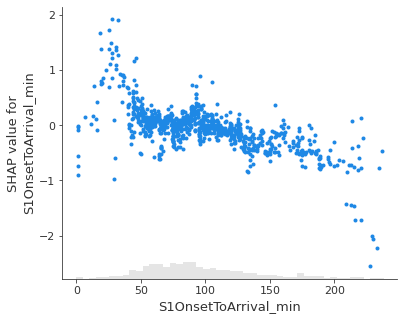
Show the relationship between feature value and Shap value for top 5 influential features.#
feat_to_show = top_10_shap[0:5]
for feat in feat_to_show:
shap.plots.scatter(shap_values_extended[:, feat], x_jitter=0)
Showing waterfall plots using probability values#
Though Shap values for XGBoost most accurately describe the effect on log odds ratio of classification, it may be easier for people to understand influence of features using probabilities. Here we plot waterfall plots using probabilities.
A disadvantage of this method is that it distorts the influence of features someone - those features pushing the probability down from a low level to an even lower level get ‘squashed’ in apparent importance. This distortion is avoided when plotting log odds ratio, but at the cost of using an output that is poorly understandable by many.
# Set up explainer using typical feature values from training set
explainer = shap.TreeExplainer(model, X_train, model_output='probability')
# Get Shapley values along with base and features
shap_values_extended = explainer(X_test)
shap_values = shap_values_extended.values
# Get the location of an example each of low and high probablility
location_low_probability = np.where(y_prob==np.min(y_prob))[0][0]
location_high_probability = np.where(y_prob==np.max(y_prob))[0][0]
An example with low probability of receiving thrombolysis.
fig = shap.plots.waterfall(shap_values_extended[location_low_probability],
show=False, max_display=8)
plt.savefig(
'output/xgb_decision_comparison_waterfall_low_probability_key_features.jpg',
dpi=300, bbox_inches='tight', pad_inches=0.2)
plt.show()
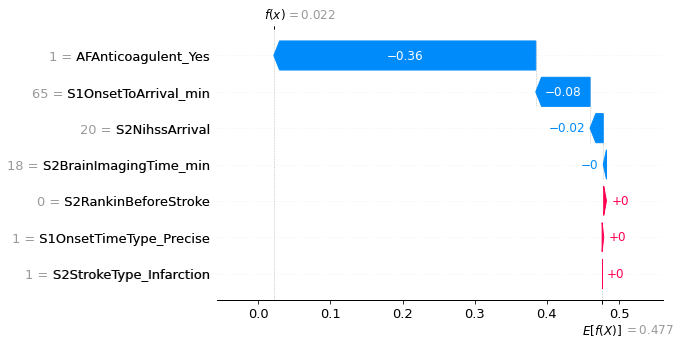
An example with high probability of receiving thrombolysis.
fig = shap.plots.waterfall(shap_values_extended[location_high_probability],
show=False, max_display=8)
plt.savefig(
'output/xgb_decision_comparison_waterfall_high_probability_key_features.jpg',
dpi=300, bbox_inches='tight', pad_inches=0.2)
plt.show()
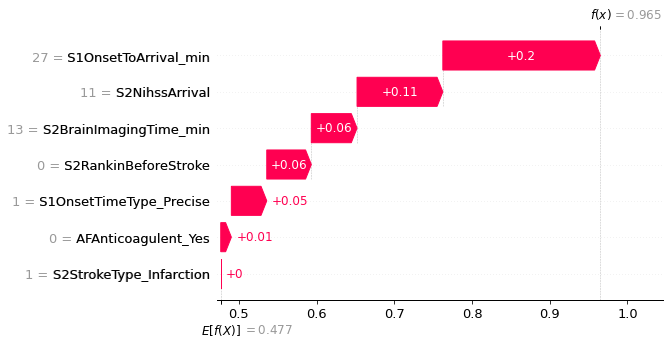
Observations#
We can predict those that will receive thrombolysis at a local unit, out of those who will be thrombolysed by the majority of the benchmark hospitals, with 68% accuracy (AUC 0.737).
The five most important distinguishing features are:
S2NihssArrival
S2RankinBeforeStroke
S1OnsetTimeType_Precise
S2BrainImagingTime_min
S1OnsetToArrival_min