Pathway patterns throughout the week
Contents
Pathway patterns throughout the week#
Aims#
Show key pathway statistics broken down by day of week
Import libraries and data#
Data has been restricted to stroke teams with at least 300 admissions, with at least 10 patients receiving thrombolysis, over three years.
# import libraries
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Display entire dataframes
pd.set_option("display.max_rows", 999, "display.max_columns", 150)
# import data
raw_data = pd.read_csv(
'./../data/2019-11-04-HQIP303-Exeter_MA.csv', low_memory=False)
headings = list(raw_data)
print (headings)
['StrokeTeam', 'PatientUID', 'Pathway', 'S1AgeOnArrival', 'MoreEqual80y', 'S1Gender', 'S1Ethnicity', 'S1OnsetInHospital', 'S1OnsetToArrival_min', 'S1OnsetDateType', 'S1OnsetTimeType', 'S1ArriveByAmbulance', 'S1AdmissionHour', 'S1AdmissionDay', 'S1AdmissionQuarter', 'S1AdmissionYear', 'CongestiveHeartFailure', 'Hypertension', 'AtrialFibrillation', 'Diabetes', 'StrokeTIA', 'AFAntiplatelet', 'AFAnticoagulent', 'AFAnticoagulentVitK', 'AFAnticoagulentDOAC', 'AFAnticoagulentHeparin', 'S2INR', 'S2INRHigh', 'S2INRNK', 'S2NewAFDiagnosis', 'S2RankinBeforeStroke', 'Loc', 'LocQuestions', 'LocCommands', 'BestGaze', 'Visual', 'FacialPalsy', 'MotorArmLeft', 'MotorArmRight', 'MotorLegLeft', 'MotorLegRight', 'LimbAtaxia', 'Sensory', 'BestLanguage', 'Dysarthria', 'ExtinctionInattention', 'S2NihssArrival', 'S2BrainImagingTime_min', 'S2StrokeType', 'S2Thrombolysis', 'Haemorrhagic', 'TimeWindow', 'Comorbidity', 'Medication', 'Refusal', 'Age', 'Improving', 'TooMildSevere', 'TimeUnknownWakeUp', 'OtherMedical', 'S2ThrombolysisTime_min', 'S2TIAInLastMonth']
Restrict original data to hospitals with at least 300 admissions + 10 thrombolysis patients#
keep = []
groups = raw_data.groupby('StrokeTeam') # creates a new object of groups of data
for index, group_df in groups: # each group has an index and a dataframe of data
# Skip if total admissions less than 300 or total thrombolysis < 10
admissions = group_df.shape[0]
thrombolysis_received = group_df['S2Thrombolysis'] == 'Yes'
if (admissions < 300) or (thrombolysis_received.sum() < 10):
continue
else:
keep.append(group_df)
# Concatenate output
data = pd.DataFrame()
data = pd.concat(keep)
Remove in-hospital onset
mask = data['S1OnsetInHospital'] == 'No'
data = data[mask]
Group by day of week#
# Work on copy of data
data_time = data.copy()
# Set up results DataFrame
day_summary = pd.DataFrame()
# Count arrivals
day_summary['Arrivals'] = \
data_time.groupby('S1AdmissionDay').count()['StrokeTeam']
# Get thrombolysis rate
thrombolysed = data_time['S2Thrombolysis'] == 'Yes'
data_time['thrombolysed'] = thrombolysed
day_summary['thrombolyse_all'] = \
data_time.groupby('S1AdmissionDay').mean()['thrombolysed']
# Get proportion of strokes with known onset
onset_known = (data_time['S1OnsetTimeType'] == 'Best estimate') | \
(data_time['S1OnsetTimeType'] == 'Precise')
data_time['onset_known'] = onset_known
day_summary['onset_known'] = \
data_time.groupby('S1AdmissionDay').mean()['onset_known']
# Get proportion over 80
data_time['age_80_plus'] = data_time['MoreEqual80y'] == 'Yes'
day_summary['age_80_plus'] = \
data_time.groupby('S1AdmissionDay').mean()['age_80_plus']
# Get Rankin score
day_summary['rankin_all'] = \
data_time.groupby('S1AdmissionDay').mean()['S2RankinBeforeStroke']
# Get NIHSS
day_summary['nihss_all'] = \
data_time.groupby('S1AdmissionDay').mean()['S2NihssArrival']
# Get onset to arrival <4hrs and then restrict data
data_time['4hr_arrival'] = data_time['S1OnsetToArrival_min'] <= 240
day_summary['4hr_arrival'] = \
data_time.groupby('S1AdmissionDay').mean()['4hr_arrival']
mask = data_time['4hr_arrival']
data_time = data_time[mask]
# Get Rankin score of arrivals within 4hrs onset
day_summary['rankin_4hr'] = \
data_time.groupby('S1AdmissionDay').mean()['S2RankinBeforeStroke']
# Get NIHSS of arrivals within 4hrs onset
day_summary['nihss_4hr'] = \
data_time.groupby('S1AdmissionDay').mean()['S2NihssArrival']
# Get onset to arrival (of those arriving within 4 hours)
day_summary['onset_arrival'] = \
data_time.groupby('S1AdmissionDay').mean()['S1OnsetToArrival_min']
# Get scan in four hours (and remove rest)
data_time['4hr_scan'] = data_time['S2BrainImagingTime_min'] <= 240
day_summary['scan_4hrs'] = \
data_time.groupby('S1AdmissionDay').mean()['4hr_scan']
mask = data_time['4hr_scan']
data_time = data_time[mask]
# Get arrival to scan (of those arriving within 4 hours and scanned in 4hrs)
day_summary['arrival_scan'] = \
data_time.groupby('S1AdmissionDay').mean()['S2BrainImagingTime_min']
# Filter down to acanned within 4 hrs onset
onset_to_scan = (
data_time['S1OnsetToArrival_min'] + data_time['S2BrainImagingTime_min'])
data_time['onset_to_scan'] = onset_to_scan
mask = data_time['onset_to_scan'] <= 240
data_time = data_time[mask]
# Get thrombolysis given and remove rest
day_summary['thrombolyse_4hr'] = \
data_time.groupby('S1AdmissionDay').mean()['thrombolysed']
mask = data_time['thrombolysed']
# Get scan to needle
scan_to_needle = (
data_time['S2ThrombolysisTime_min'] - data_time['S2BrainImagingTime_min'])
data_time['scan_needle'] = scan_to_needle
day_summary['scan_to_needle'] = \
data_time.groupby('S1AdmissionDay').mean()['scan_needle']
# Get arrival to needle
day_summary['arrival_to_needle'] = \
data_time.groupby('S1AdmissionDay').mean()['S2ThrombolysisTime_min']
# Get onset to needle
onset_to_needle = (
data_time['S1OnsetToArrival_min'] + data_time['S2ThrombolysisTime_min'])
data_time['onset_to_needle'] = onset_to_needle
day_summary['onset_to_needle'] = \
data_time.groupby('S1AdmissionDay').mean()['onset_to_needle']
# Sort by day
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday',
'Sunday']
day_summary = day_summary.loc[day_order]
day_summary['Weekday'] = ['Mo', 'Tu', 'We', 'Th', 'Fr', 'Sa', 'Su']
Show summary table by day of week#
day_summary.T
| S1AdmissionDay | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
|---|---|---|---|---|---|---|---|
| Arrivals | 35509 | 33378 | 33031 | 32813 | 33162 | 29423 | 29504 |
| thrombolyse_all | 0.111577 | 0.114357 | 0.118404 | 0.118612 | 0.119444 | 0.120858 | 0.126085 |
| onset_known | 0.649272 | 0.664929 | 0.666949 | 0.662512 | 0.663832 | 0.69048 | 0.688144 |
| age_80_plus | 0.408404 | 0.41054 | 0.414762 | 0.415689 | 0.413606 | 0.427863 | 0.42601 |
| rankin_all | 1.02563 | 1.02322 | 1.0511 | 1.05065 | 1.04758 | 1.08004 | 1.05979 |
| nihss_all | 7.14126 | 7.34329 | 7.4493 | 7.4208 | 7.36991 | 7.83193 | 7.80908 |
| 4hr_arrival | 0.367203 | 0.385643 | 0.394993 | 0.39015 | 0.385622 | 0.415763 | 0.411707 |
| rankin_4hr | 1.04456 | 1.0397 | 1.07274 | 1.06991 | 1.05654 | 1.08248 | 1.05269 |
| nihss_4hr | 9.04067 | 9.16235 | 9.11088 | 9.1673 | 9.32718 | 9.31422 | 9.40097 |
| onset_arrival | 112.629 | 111.474 | 112.068 | 111.269 | 111.187 | 110.951 | 110.045 |
| scan_4hrs | 0.943017 | 0.948027 | 0.950027 | 0.948211 | 0.951439 | 0.946538 | 0.947971 |
| arrival_scan | 42.0403 | 42.1736 | 41.734 | 41.3271 | 41.8938 | 43.0012 | 42.6163 |
| thrombolyse_4hr | 0.35727 | 0.344918 | 0.347802 | 0.350107 | 0.355512 | 0.338662 | 0.357744 |
| scan_to_needle | 36.0123 | 34.7655 | 34.5564 | 33.944 | 34.6868 | 39.9146 | 39.3693 |
| arrival_to_needle | 59.0387 | 57.1304 | 56.6897 | 56.0211 | 56.6341 | 62.9738 | 62.4921 |
| onset_to_needle | 155.33 | 152.912 | 151.984 | 152.409 | 151.844 | 157.17 | 156.522 |
| Weekday | Mo | Tu | We | Th | Fr | Sa | Su |
Show summary charts of key metrics by day of week#
# Set up figure
fig = plt.figure(figsize=(12,15))
# Subplot 1: Arrivals
ax1 = fig.add_subplot(4,4,1)
x = day_summary['Weekday']
y = day_summary['Arrivals'] / day_summary['Arrivals'].sum() * 7
ax1.plot(x,y)
# Add line at 1
y1 = np.repeat(1,7)
ax1.plot(x,y1, color='0.5', linestyle=':')
ax1.set_ylim(ymin=0) # must be after plot method
ax1.set_xlabel('Day of week')
ax1.set_ylabel('Normlalised arrivals')
ax1.set_title('Arrivals\n(normalised to average)')
# Subplot 2: Thrombolysis
ax2 = fig.add_subplot(4,4,2)
x = day_summary['Weekday']
y = day_summary['thrombolyse_all'] * 100
ax2.plot(x,y)
ax2.set_xlabel('Day of week')
ax2.set_ylabel('Thrombolysis (%)')
ax2.set_title('Thrombolysis use\n(all arrivals)')
# Subplot 3: Known onset
ax3 = fig.add_subplot(4,4,3)
x = day_summary['Weekday']
y = day_summary['onset_known'] * 100
ax3.plot(x,y)
ax3.set_xlabel('Day of week')
ax3.set_ylabel('Onset known (%)')
ax3.set_title('Proportion with known onset')
# Subplot 4: age_80_plus
ax4 = fig.add_subplot(4,4,4)
x = day_summary['Weekday']
y = day_summary['age_80_plus'] * 100
ax4.plot(x,y)
ax4.set_xlabel('Day of week')
ax4.set_ylabel('Aged 80+')
ax4.set_title('Proportion aged 80+')
# Subplot 5: Rankin (all arrivals)
ax5 = fig.add_subplot(4,4,5)
x = day_summary['Weekday']
y = day_summary['rankin_all']
ax5.plot(x,y)
ax5.set_xlabel('Day of week')
ax5.set_ylabel('Rankin (mean)')
ax5.set_title('Mean pre-stroke\nmodified Rankin\n(all arrivals)')
# Subplot 6: NIHSS (all arrivals)
ax6 = fig.add_subplot(4,4,6)
x = day_summary['Weekday']
y = day_summary['nihss_all']
ax6.plot(x,y)
ax6.set_xlabel('Day of week')
ax6.set_ylabel('NIHSS (mean)')
ax6.set_title('Mean NIH Stroke Scale\n(all arrivals)')
# Subplot 7: 4hr_arrival
ax7 = fig.add_subplot(4,4,7)
x = day_summary['Weekday']
y = day_summary['4hr_arrival'] * 100
ax7.plot(x,y)
ax7.set_xlabel('Day of week')
ax7.set_ylabel('Arrive within 4hrs of onset (%)')
ax7.set_title('Proportion arriving within\n4hrs of known onset')
# Subplot 8: Rankin (4hr arrivals)
ax8 = fig.add_subplot(4,4,8)
x = day_summary['Weekday']
y = day_summary['rankin_4hr']
ax8.plot(x,y)
ax8.set_xlabel('Day of week')
ax8.set_ylabel('Rankin (mean)')
ax8.set_title('Mean pre-stroke\nmodified Rankin\n(arrivals 4hrs from onset)')
# Subplot 9: NIHSS (4hr arrivals)
ax9 = fig.add_subplot(4,4,9)
x = day_summary['Weekday']
y = day_summary['nihss_4hr']
ax9.plot(x,y)
ax9.set_xlabel('Day of week')
ax9.set_ylabel('NIHSS (mean)')
ax9.set_title('Mean NIH Stroke Scale\n(arrivals 4hrs from onset)')
# Subplot 10: onset_arrival (4hr arrivals)
ax10 = fig.add_subplot(4,4,10)
x = day_summary['Weekday']
y = day_summary['onset_arrival']
ax10.plot(x,y)
ax10.set_xlabel('Day of week')
ax10.set_ylabel('Onset to arrival (minutes, mean)')
ax10.set_title('Mean onset to arrival\n(arrivals 4hrs from onset)')
# Subplot 11: scan_4hrs (4hr arrivals)
ax11 = fig.add_subplot(4,4,11)
x = day_summary['Weekday']
y = day_summary['scan_4hrs'] * 100
ax11.plot(x,y)
ax11.set_xlabel('Day of week')
ax11.set_ylabel('Proportion scanned within 4hrs (%)')
ax11.set_title('Proportion scanned within\n4hrs of arrival\n(arrivals 4hrs from onset)')
# Subplot 12: arrival_scan (4hr scan)
ax12 = fig.add_subplot(4,4,12)
x = day_summary['Weekday']
y = day_summary['arrival_scan']
ax12.plot(x,y)
ax12.set_xlabel('Day of week')
ax12.set_ylabel('Arrival to scan (minutes, mean)')
ax12.set_title('Mean arrival to scan\n(scanned 4hrs from onset)')
# Subplot 13: thrombolysis (4hr scan)
ax13 = fig.add_subplot(4,4,13)
x = day_summary['Weekday']
y = day_summary['thrombolyse_4hr'] * 100
ax13.plot(x,y)
ax13.set_xlabel('Day of week')
ax13.set_ylabel('Thrombolsyis(%)')
ax13.set_title('Thrombolysis use\n(scanned 4hrs from onset)')
# Subplot 14: scan_to_needle
ax14 = fig.add_subplot(4,4,14)
x = day_summary['Weekday']
y = day_summary['scan_to_needle']
ax14.plot(x,y)
ax14.set_xlabel('Day of week')
ax14.set_ylabel('Scan to needle (minutes, mean)')
ax14.set_title('Mean scan to needle')
# Subplot 15: arrival_to_needle
ax15 = fig.add_subplot(4,4,15)
x = day_summary['Weekday']
y = day_summary['arrival_to_needle']
ax15.plot(x,y)
ax15.set_xlabel('Day of week')
ax15.set_ylabel('Arrival to needle (minutes, mean)')
ax15.set_title('Mean arrival to needle')
# Subplot 16: onset_to_needle
ax16 = fig.add_subplot(4,4,16)
x = day_summary['Weekday']
y = day_summary['onset_to_needle']
ax16.plot(x,y)
ax16.set_xlabel('Day of week')
ax16.set_ylabel('Onset to needle (minutes, mean)')
ax16.set_title('Mean onset to needle')
# Save and show
plt.tight_layout(pad=2)
plt.savefig('output/stats_by_day_of_week.jpg', dpi=300)
plt.show();
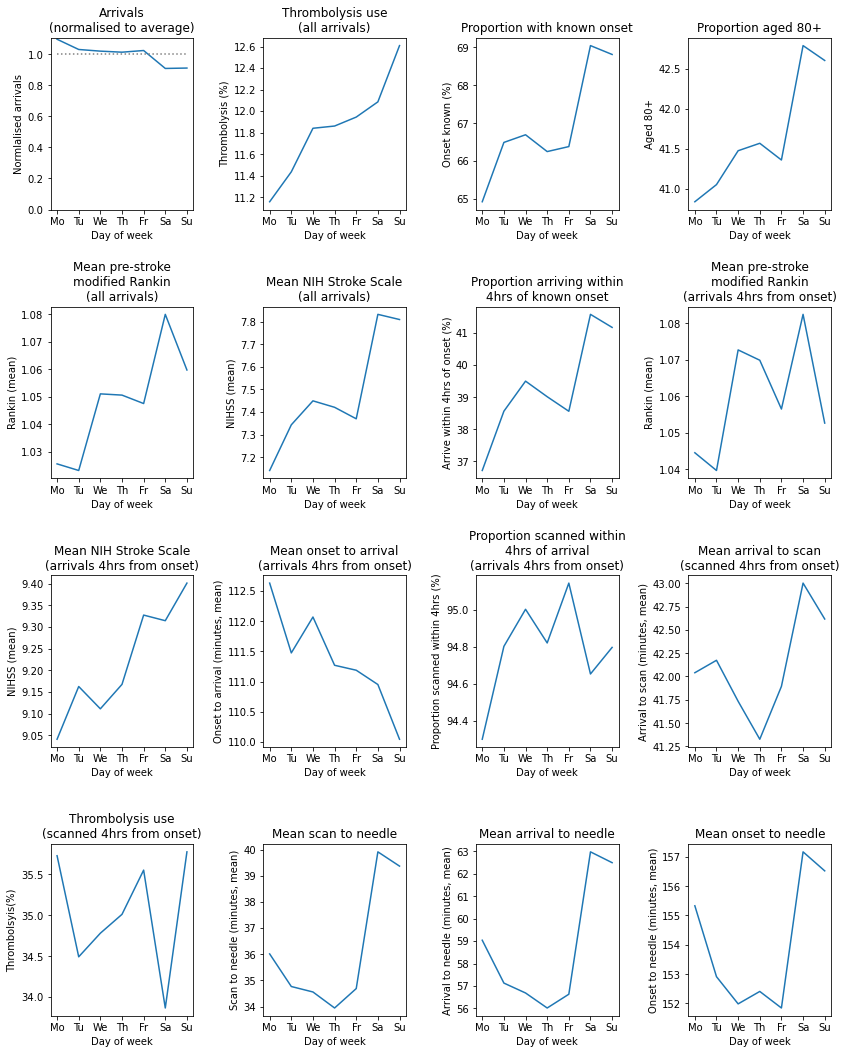
Observations#
Variation in thrombolysis use across the week is about 1.5 percentage points, with weekends having slightly higher thrombolysis use than weekdays.
Generally patterns by weekday are weak when considered at a national average level.