Assessing accuracy of models with stratified k-fold cross-validation
Assessing accuracy of models with stratified k-fold cross-validation#
When assessing accuracy of the machine learning models, stratified k-fold splits were used (Figure 14) We used 5-fold splits where each data point is in one, and only one, of five test sets. This is represented schematically below. Data is stratified such that the test set is representative of hospital mix in the whole data population, and within the hospital level data the use of thrombolysis is representative of the whole data for that hospital.
All models were trained and tested using data for patients arriving within 4 hours of known stroke onset (39% of all patients), and was restricted to hospitals receiving at least 300 patients over three years, and giving thrombolysis to at least 10 patients over three years.
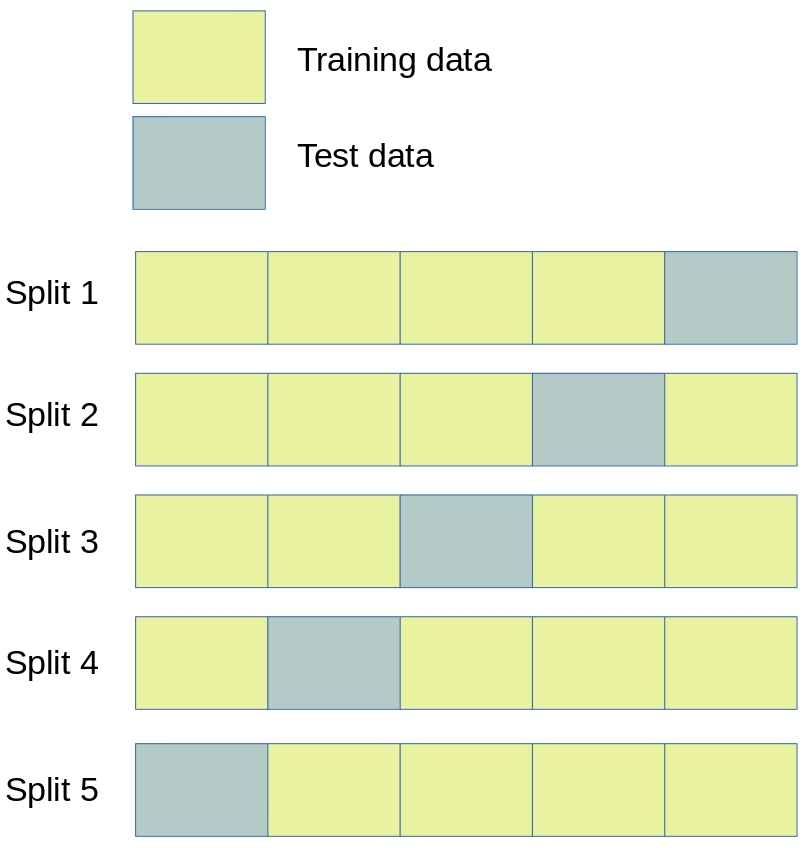
Fig. 14 Schematic of how k-fold validation splits data so that all examples are in one, but only one, test set.]#